
阅读量:4
数字经济时代,算力成为支撑经济社会发展新的关键生产力,全球主要经济体都在加快推进算力战略布局。随着大模型持续选代,模型能力不断增强,带来算力需求持续增长。算力对数字经济和GDP的提高有显著的带动作用,根据IDC、浪潮信息、清华大学联合发布的数据显示,计算力指数平均每提高1点,数字经济和GDP将分别增长3.5‰和1.8‰。
算力是芯片单位时间里处理数据的能力,算力越高,单位时间里处理的数据量越大,作为新质生产力的重要代表的智能算力网络,正在推动社会进步和经济发展。以1000 亿参数的大模型为例,预训练、推理、调优三个环节的算力总需求约18万PFlop/s-day,对应需要 2.8 万张 A100 等效的 GPU 算力。
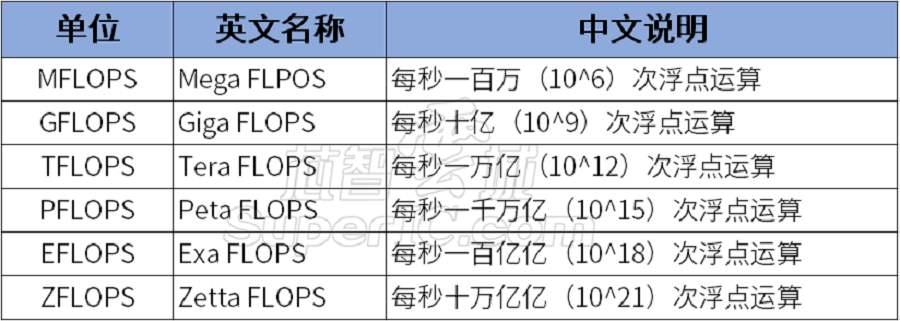
图1:常见算力单位
根据工信部数据,我国在用数据中心机架总规模超过810万标准机架,算力总规模位居全球第二,达到了230EFLOPS,就是每秒230百亿亿次浮点运算,预计到2025年,我国算力总规模将突破300EFLOPS,由GPU、TPU、NPU带来的智能算力占比将达到35%。罗兰贝格的预测,从2018年到2030年,自动驾驶对算力的需求将增加390倍,智慧工厂需求将增长110倍,主要国家人均算力需求将从今天的不足500 GFLOPS,增加20倍,变成2035年的10000 GFLOPS。目前算力正加速向政务、工业、交通、医疗等各行业各领域渗透,未来算力产业将成为我国经济增长的重要引擎之一。
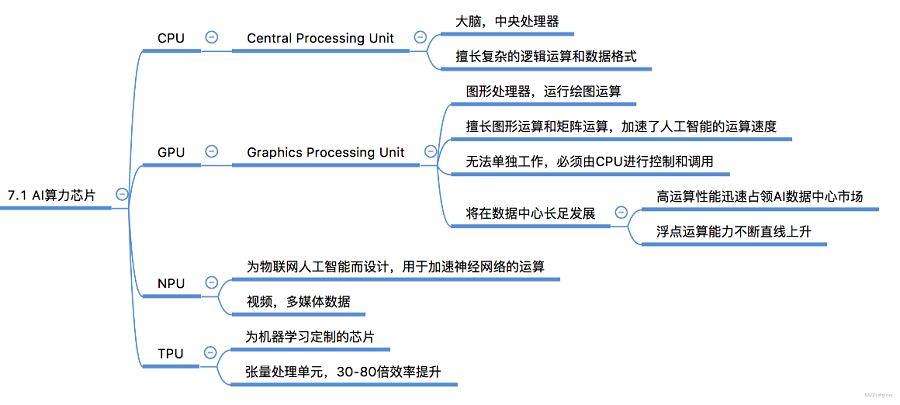
图2:AI算力芯片种类
GPU(Graphics Processing Unit)是一种主要用于图形渲染和加速图形处理任务的专用处理器,具备大量核心和高度并行的架构,特别适合处理图形渲染、影像处理和科学计算领域,因其在处理各种 AI 任务方面的多功能性而闻名,包括训练深度学习模型和执行推理操作。 而以CPU提供算力,适合复杂逻辑运算,比如大多数通用软件。
TPU:张量处理器(Tensor Processing Unit)是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计,由于相比GPU牺牲了处理器的通用型,可快速高效地执行张量运算,因此在特定任务中TPU的性能表现更佳。例如,在 V100 GPU 上使用 BERT 模型处理一批 128 个序列需要 3.8 毫秒,而在 TPU v3 上则需要 1.7 毫秒。
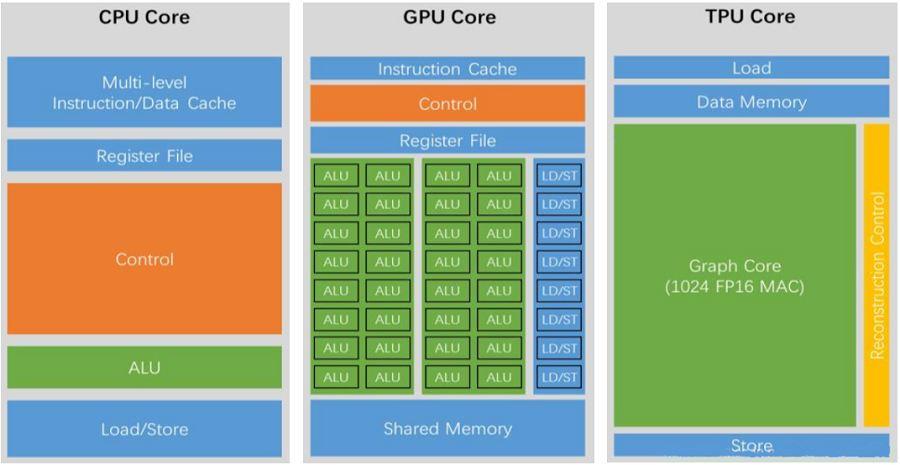
图3:CPU、GPU和TPU的芯片架构区别
张量处理器(TPU)与图形处理器(GPU)相比,具备如下特点:
(1)TPU采用低精度(8位)计算,可以减少每步操作使用的晶体管数量,而降低精度对于深度学习的准确度影响很小,但却可以大幅降低功耗、加快运算速度。
(2)TPU使用了脉动阵列的设计,用来优化矩阵乘法与卷积运算,减少I/O操作。
(3)TPU还采用了更大的片上内存以减少对DRAM的访问,从而更大程度地提升性能。
这种专业化通常使 TPU 在特定的深度学习任务(尤其是经过 Google 优化的任务)中表现优于 GPU,例如广泛的神经网络训练和复杂的机器学习模型。谷歌2024年5月发布第六代张量处理器Trillium,芯片的峰值计算性能提高4.7倍达到约925.9 teraflops,能效指标也比上一代提升67%。
一、算能(SOPHGO)简介

算能(SOPHGO)成立于2020年,总部位于北京市,公司致力于成为全球领先的定制算力提供商。算能科技汇聚了大量芯片、算法、AI、CPU等领域的专业技术人才,研发人员比例超过60%,其中硕博士超过61%。算能科技与比特大陆(BITMAIN)在AI领域有技术、专利、产品和客户的共享,继承了比特大陆在AI领域的技术积累,专注于AI芯片、RISC-V CPU等算力产品的研发和销售。
算能公司遵循全面开源开放的生态理念,携手行业伙伴推动RISC-V高性能通用计算产业落地;打造覆盖“云、边、端”的全场景产品矩阵,为数据中心、AIGC、城市运营、智能制造、智能终端等多元场景提供算力产品及整体解决方案。产品已广泛应用在智能视频、智能安防、智能交通、智能电力、智能医疗、智能油气、智能语义、智能推荐、城市大脑等场景。
二、算能(SOPHGO)产品系列
2.1处理器芯片
算能提供RISC-V、TPU两大系列产品,应用领域包括云端、边缘计算以及终端产品,可以提供定制算力和专用算力两大领域。

图4:算能针对定制算力和专用算力芯片
(1)TPU处理器芯片

图5:算能应用于云端和边缘计算的TPU芯片
(2)RISC-V处理器

图6:算能RISC-V通用算力芯片
2.2 服务器和微服务器
(1)智算服务器

图7:算能边缘智算服务器系列
(2)微服务器

图8:算能边缘智算“微服务器”系列

图9:算能TPU芯片在边缘智算服务器上的应用
2.3 模组&卡
(1)智算卡
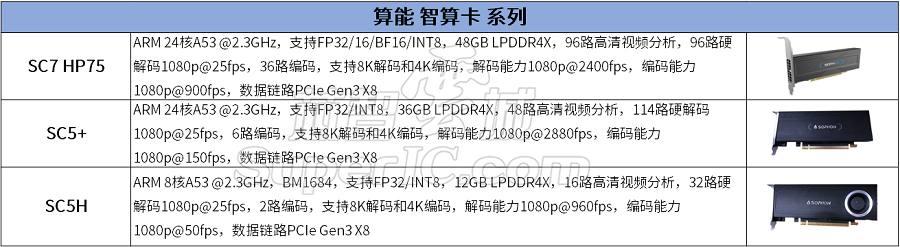
图10:算能PCIe接口云端智算卡系列
(2)智算模组
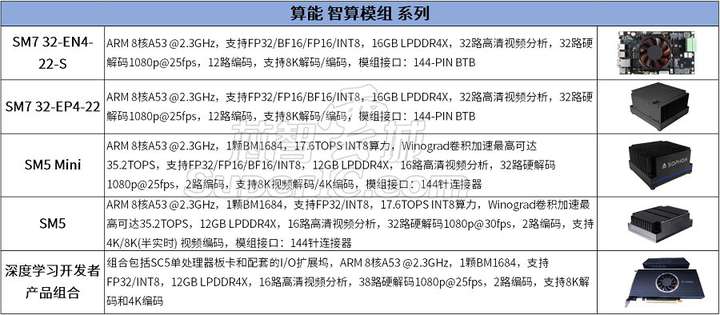
图11:算能云端智算模块系列

图12:算能TPU在云端智算板卡/模组上的应用

图13:算能RISC-V处理器芯片和应用

图14:算能AI PC解决方案
三、算能(SOPHGO)智算行业解决方案
算能解决方案助力数字中国建设,面向丰富的业务场景,提供整套行业和技术解决方案,助力客户数字化转型,让国产算力普惠千行百业。
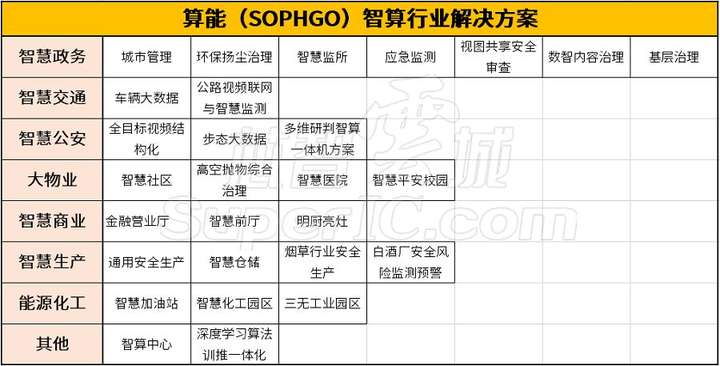
图15:算能智算行业应用方案
3.1方案特点:
(1)打破信息孤岛,实现数据结构化:整合所有联网的目标视图数据、实时动态数据等资源,打破数据孤岛,实现安全生产应用互联互通,同时确保数据安全和灵活应用。适配企业组织应用需求,支持云边端多级部署架构,运用深度学习等技术自动化数据采集、全局分析、统筹研判和分析决策。
(2)数据结构化,全面分析:采用高精准度的深度学习算法,基于大规模底库数据,融合海量视频数据、自动识别,高效感知路网状态,实现从零散数据到全面分析,实现多维结构化特征的识别及处理,并且支持算法迭代升级,所有的环节都形成“智能化、数字化、定向化”管理。
(3)实时化管控,快速响应:通过对视频资源的实时智能分析,实现7*24h的长效实时监管。通过数字化网点的网络、设备、场所、人员运行状态的实时感知与管理,完成数字化职场运营实况立体呈现。
(4)全域态感知,提升管理水平:通过接入物联网/工业互联网平台数据,实现信息化设备可视化、数字化、智能化,以模型赋能,提升企业基于模型驱动的数字化和智能化管理能力,基于全要素数据实现全域态势感知,实实在在优化企业管理模式。
(5)决策辅助,预判未来:通过深度学习打通全周期的数据链条,对人、车、物、行为等进行智能化管理及风险预控,从被动响应到主动发现,进行智能识别并在线告警,排查安全隐患,杜绝事故发生。
(6)数字化赋能,降本增效:通过深度学习赋能传统摄像头,节省智能提升改造的成本。通过多种算法来识别和管理应用场景,充分发挥云边算力资源价值,促进传统产业的智能升级。通过数据和算法赋能,达到降低人力管理成本,提高运行效率和服务效能。
(7)一体化交付,自主合规:集算法训练与推理部署等能力于一体,200多种算法全面解决深度学习项目落地过程中从数据处理、模型训练、应用部署到事件上报全流程的问题,能力更全面、迭代更灵活,体验更流畅、性能更完整、性价比更高。方案做到完全的自主知识产权,安全可控,可以满足各类行业用户的监管合规要求。
3.2 算能生态算法应用案例:

图16:算能“安全生产生态算法一体机”方案

图17:算能“通用园区生态算法一体机”方案

图18:算能“智慧城管生态算法一体机”方案

图19:算能“智慧食安生态算法一体机”方案
四、应用场景:
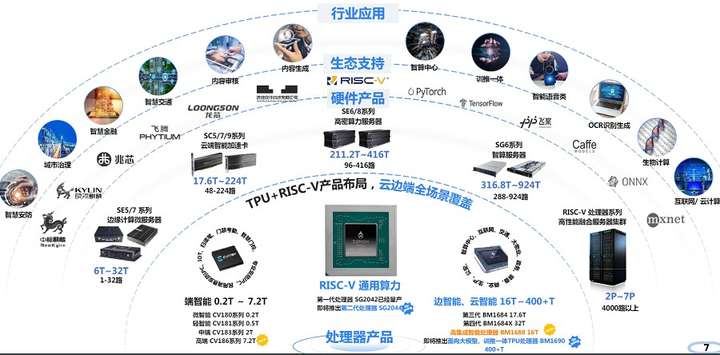
图20:算能核心业务和行业应用

图21:算能“云边端”统一工具链

图22:算能智算芯片/方案的主要行业应用领域
更多详细内容,请访问芯智雲城:算力时代,算能(SOPHGO)的算力芯片/智算板卡/服务器选型-芯智雲城
