
阅读量:1
2024年,数据中心市场,英伟达显卡依然一卡难求,已发布的A100、H100,L40S,还有即将发布的H200都是市场上的香饽饽。
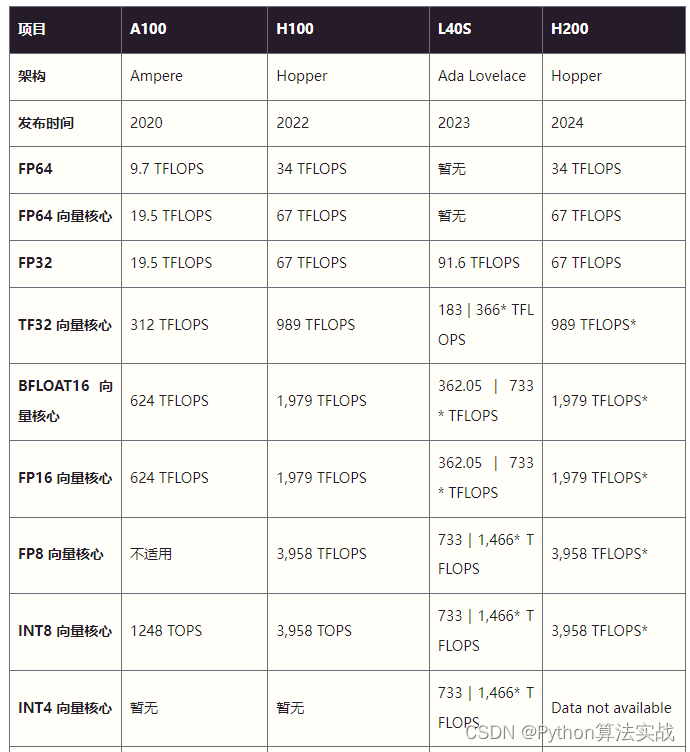
2020年,英伟达发布了基于Ampere架构的A100。2022年,英伟达发布了基于Hopper架构的H100,2023年,英伟达又发布了L40S。
2024年,英伟达即将发布H200,虽然还没正式发布,但部分规格已经公开。于是,就有了这样一张表格。
文章目录
A100

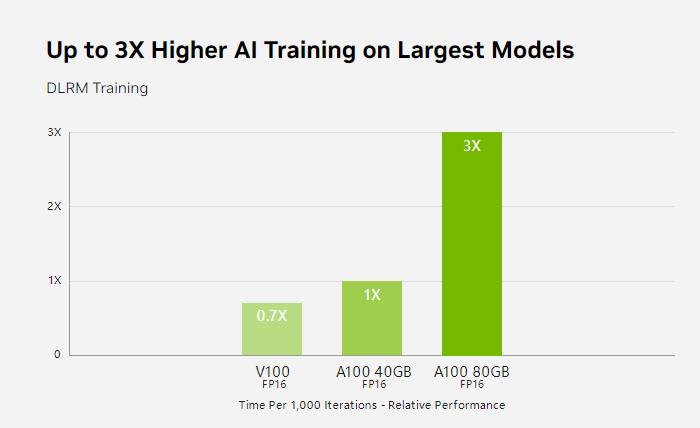
A100是2020年首次采用Ampere架构的GPU,这种架构带来显著的性能提升。
在H100发布之前,A100一览众山小。它的性能提升得益于改进的Tensor核心、更多的CUDA核心数量、更强的内存和最快的2 Tbps内存带宽。
A100支持多实例GPU功能,允许单个A100 GPU分割成多个独立的小GPU,这大大提升了云和数据中心的资源分配效率。
尽管现在已经被超越,但A100在训练复杂的神经网络、深度学习和AI学习任务方面仍然是一个优秀的选择,它的Tensor核心和高吞吐量在这些领域表现出色。
A100在AI推理任务方面表现突出,在语音识别、图像分类、推荐系统、数据分析和大数据处理、科计算场景都有优势,在基因测序和药物发现等高性能计算场景也都属于优势领域。
H100

H100能处理最具挑战性的AI工作负载和大规模数据处理任务。
H100升级了Tensor核心,显著提高了AI训练和推理的速度。支持双精度(FP64)、单精度(FP32)、半精度(FP16)和整数(INT8)计算负载。
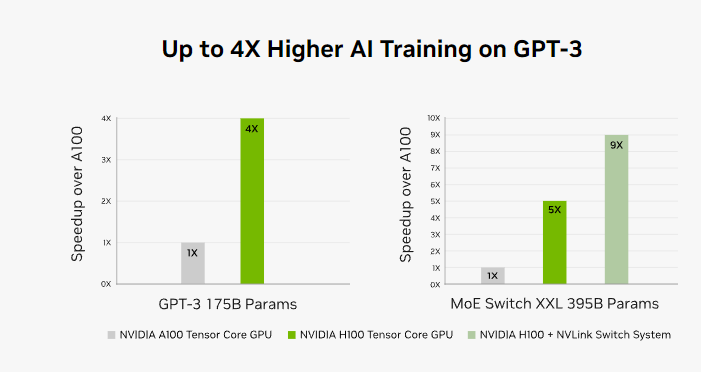
相比A100,FP8计算速度提升六倍,达到4petaflops。内存增加50%,使用HBM3高带宽内存,带宽可达3 Tbps,外部连接速度几乎达到5 Tbps。此外,新的Transformer引擎使模型转换器训练速度提升高达六倍。
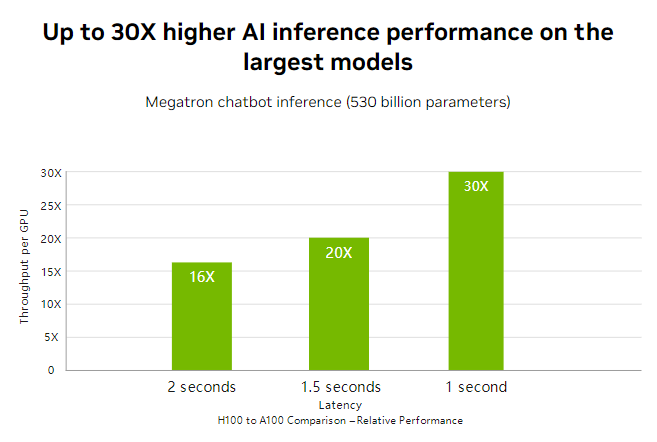
尽管H100和A100在使用场景和性能特点上有相似之处,但H100在处理大型AI模型和更复杂的科学模拟方面表现更佳。H100是高级对话式AI和实时翻译等实时响应型AI应用的更优选择。
总之,H100在AI训练和推理速度、内存容量和带宽、以及处理大型和复杂AI模型方面相比A100有显著的性能提升,适用于对性能有更高要求的AI和科学模拟任务。
L40S

L40S旨在处理下一代数据中心工作负载,包括生成式AI、大型语言模型(LLM)的推理和训练,3D图形渲染、科学模拟等场景。
与前一代GPU(如A100和H100)相比,L40S在推理性能上提高了高达5倍,在实时光线追踪(RT)性能上提高了2倍。
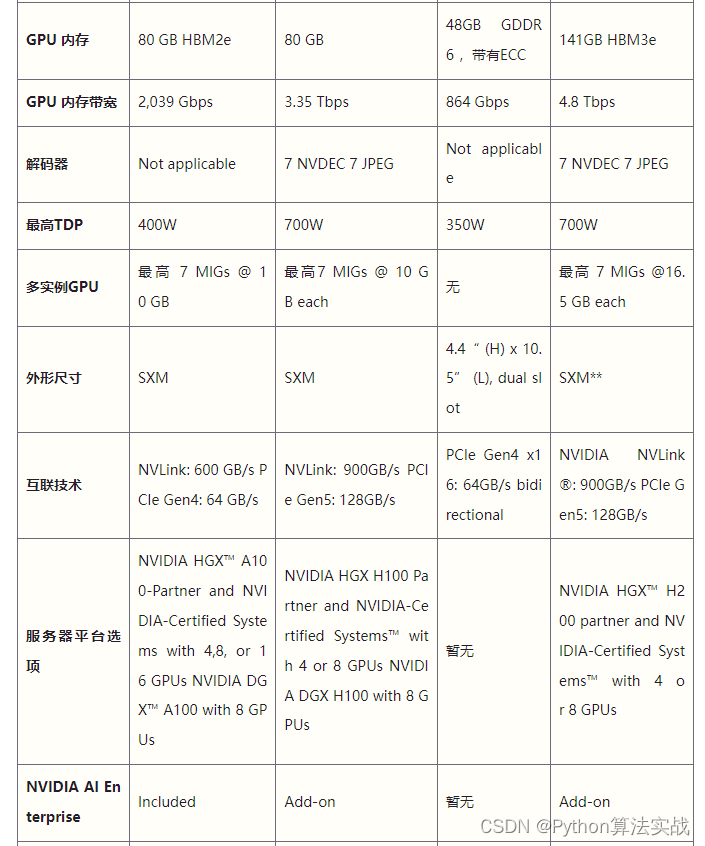
内存方面,它配备48GB的GDDR6内存,还加入了对ECC的支持,在高性能计算环境中维护数据完整性还是很重要的。
L40S配备超过18,000个CUDA核心,这些并行处理器是处理复杂计算任务的关键。
L40S更注重可视化方面的编解码能力,而H100则更专注于解码。尽管H100的速度更快,但价格也更高。从市场情况来看,L40S相对更容易获得。
综上所述,L40S在处理复杂和高性能的计算任务方面具有显著优势,特别是在生成式AI和大型语言模型训练等领域。其高效的推理性能和实时光线追踪能力使其成为数据中心不可忽视的存在。
H200

H200将是NVIDIA GPU系列中的最新产品,预计在2024年第二季度开始发货。
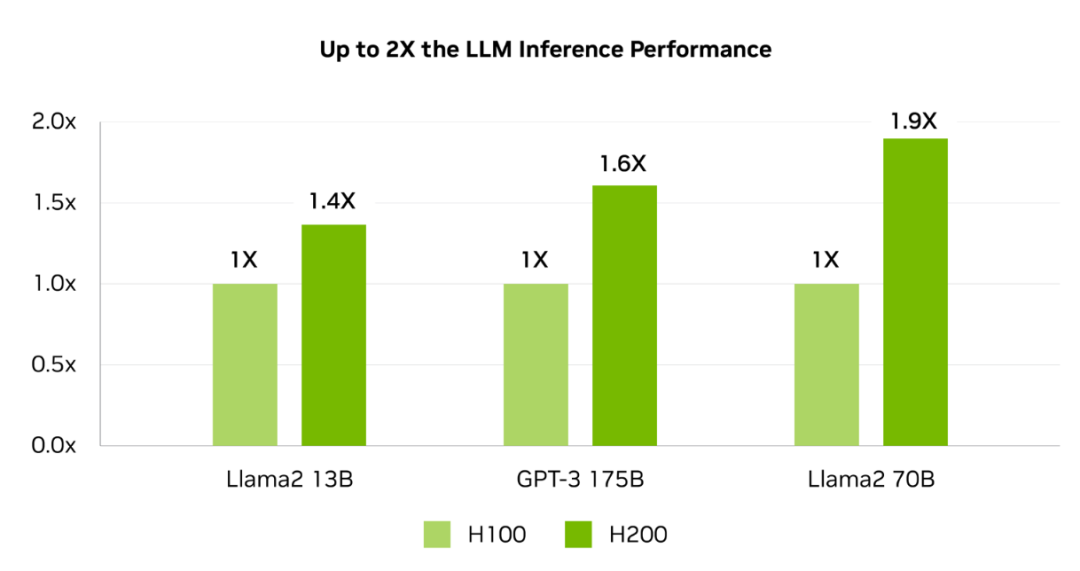
H200是首款提供141 GB HBM3e内存和4.8 Tbps带宽的GPU,其内存容量和带宽分别几乎是H100的2倍和1.4倍。
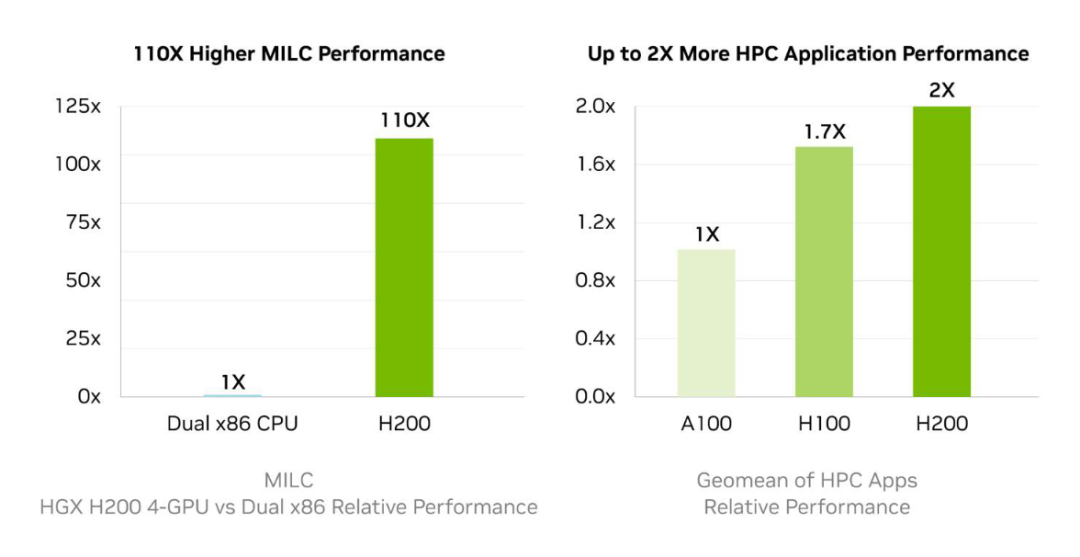
在高性能计算方面,与CPU相比,H200能实现高达110倍的加速,从而更快地得到结果。
在处理Llama2 70B推理任务时,H200的推理速度是H100 GPU的两倍。
H200将在边缘计算和物联网(IoT)应用中的人工智能物联网(AIoT)方面发挥关键作用。
在包括最大型模型(超过1750亿参数)的LLP训练和推理、生成式AI和高性能计算应用中,可以期待H200提供最高的GPU性能。
总之,H200将在AI和高性能计算领域提供前所未有的性能,特别是在处理大型模型和复杂任务时。它的高内存容量和带宽,以及优异的推理速度,使其成为处理最先进AI任务的理想选择。
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
