
阅读量:0
这里写目录标题
目标
实现的目标
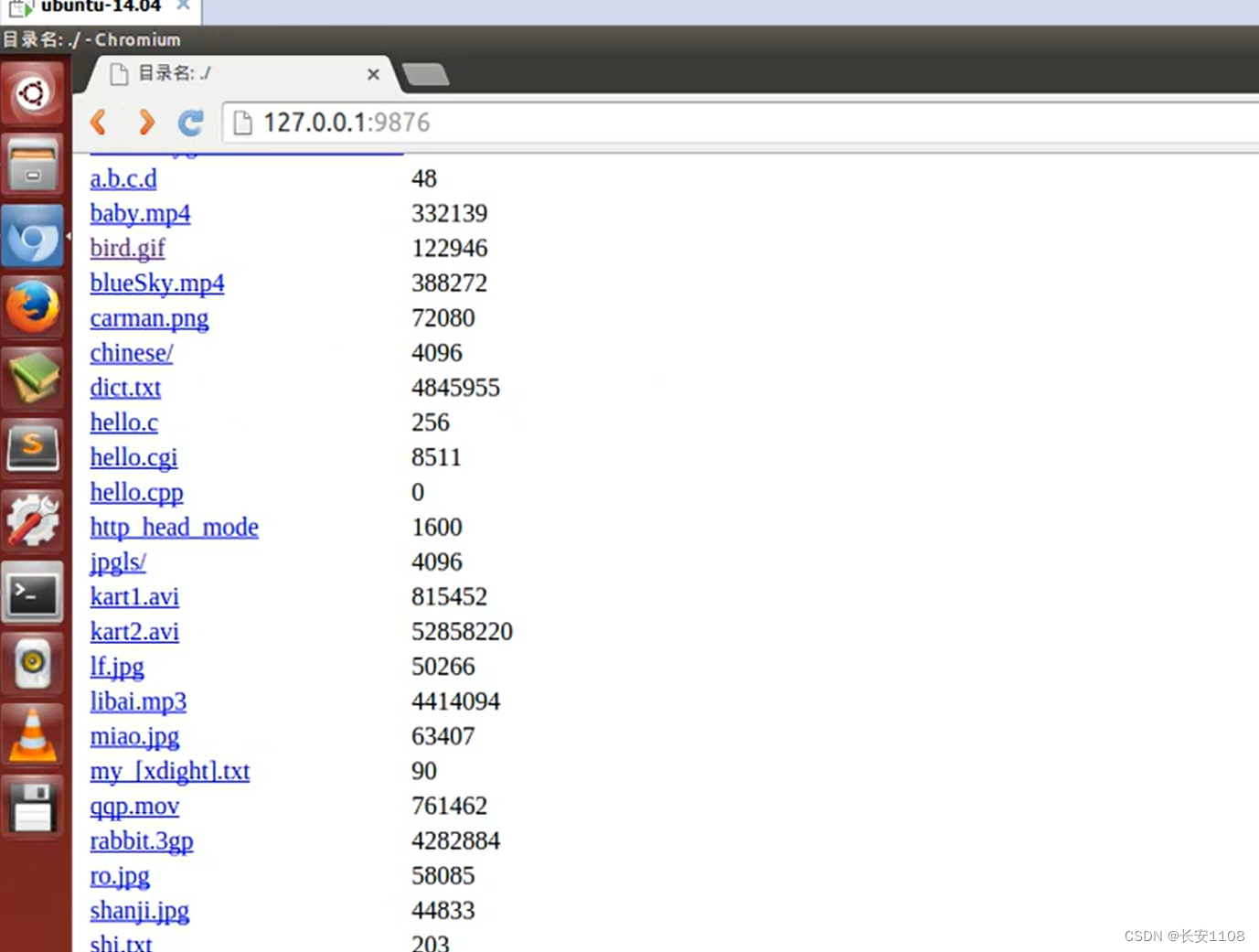
我们要实现,在服务器上启动服务之后,通过浏览器访问Ip+port,可以访问到服务器某个目录的文件
当然也可以使用域名访问,域名就是对IP+port进行了包装,域名需要申请
服务器代码(采用epoll实现服务器)
整体框架
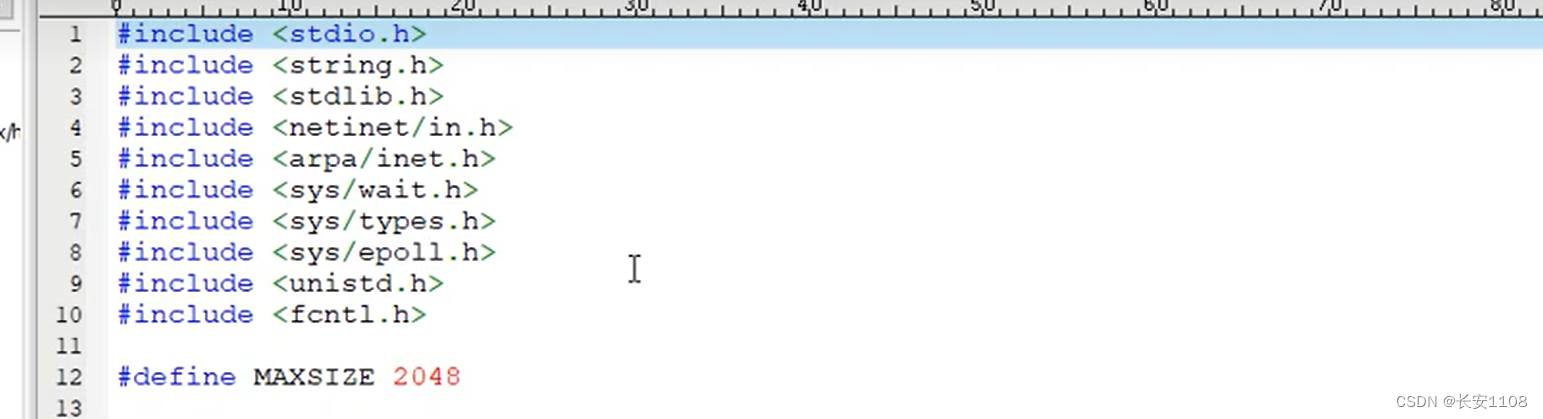
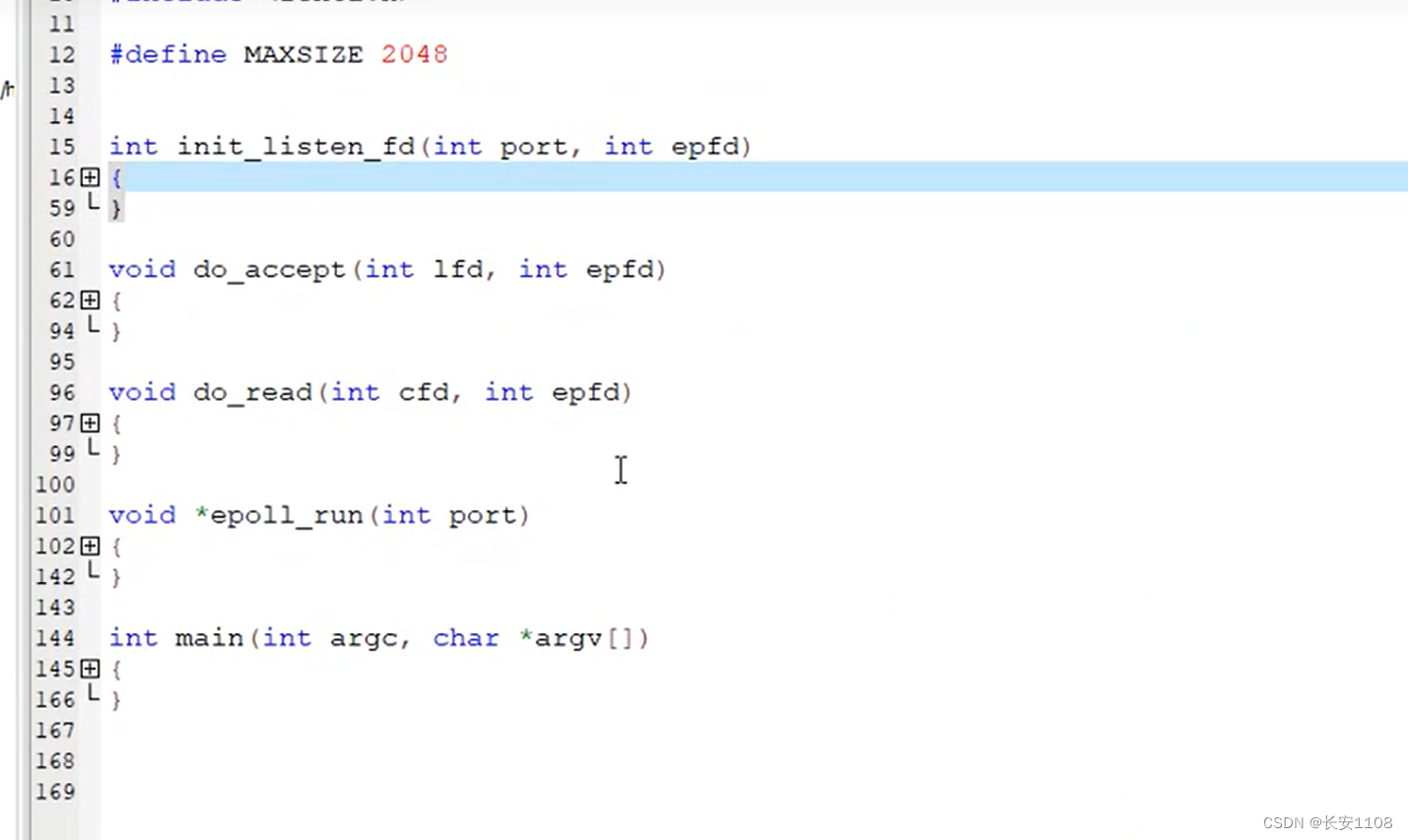
main函数
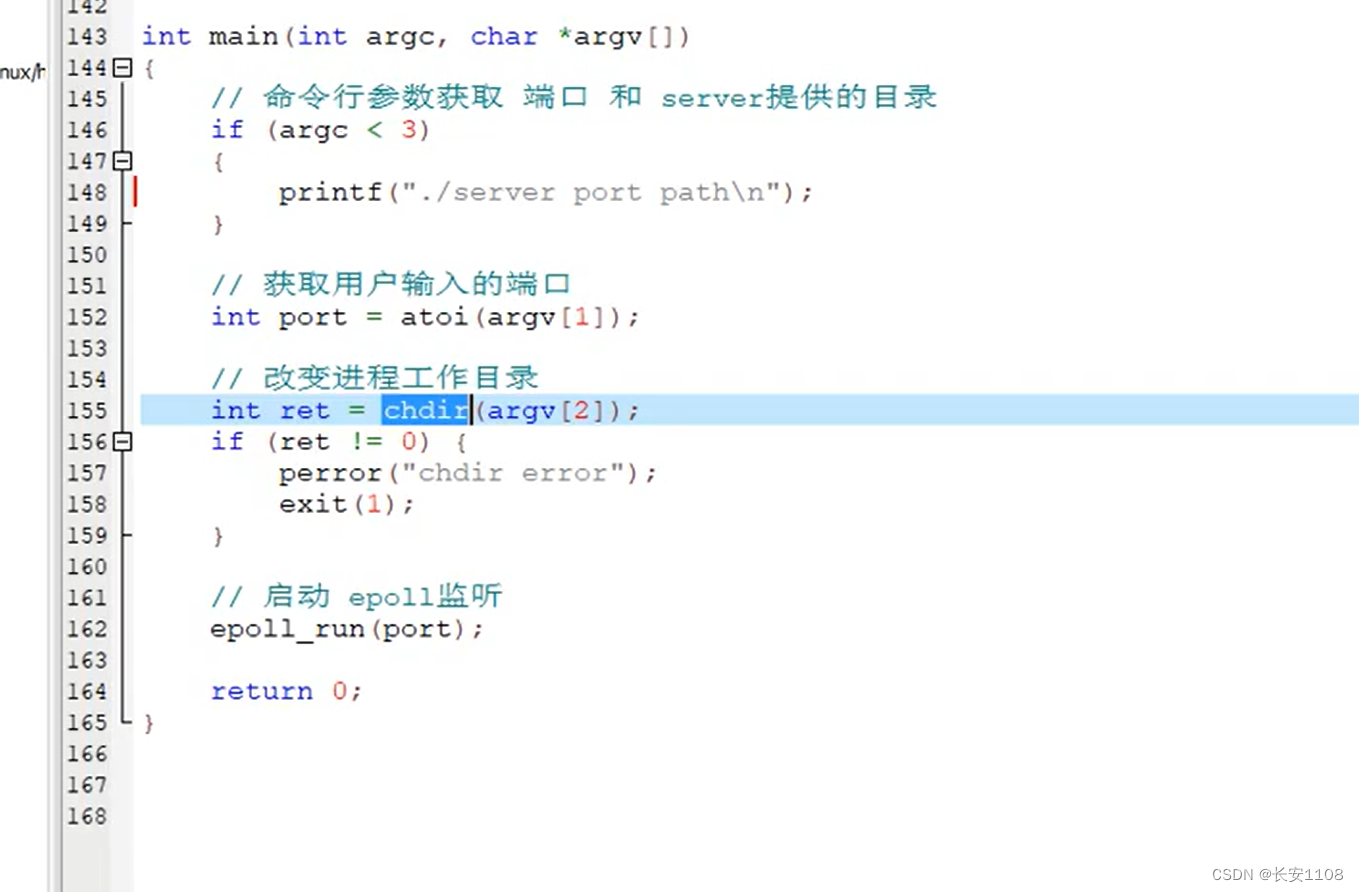
首先,为了更加灵活的进行服务端的启动,我们在main函数中,定义两个参数,用于进行启动参数的配置和读取
首先,判断argv是否读到了三个字符串,如果小于三个字符串,则启动时没有按照规定进行启动参数设置,提示启输入./server 端口 以及要发布的文件所在路径
之后,通过argv[2],拿到输入的第二个字符串,即端口,将其atoi,转为字面值一样的int型,就拿到了开放的端口
之后,因为http协议中,对于从浏览器发送而来的文件的位置,是以启动配置的第三个参数为参考根目录的相对路径,服务器要设法拿到服务器对应的路径,而拼接路径又过于繁琐,所以,使用chdir函数,该函数可以让服务端的工作目录跳转到某个目录下(实际上就是与cd的作用一样),所以,chdir(argv[2]),就是将服务器跳转到第三个参数所指明的目录内,这样,从http协议封装出来的数据包拿到的数据,可以直接拿到当前服务器使用,因为服务器的工作目录已经跳转到第三个参数的目录了
之后使用封装的函数,根据传来的端口,启动epoll监听
init_listen_fd函数(负责对lfd初始化的那一系列操作)

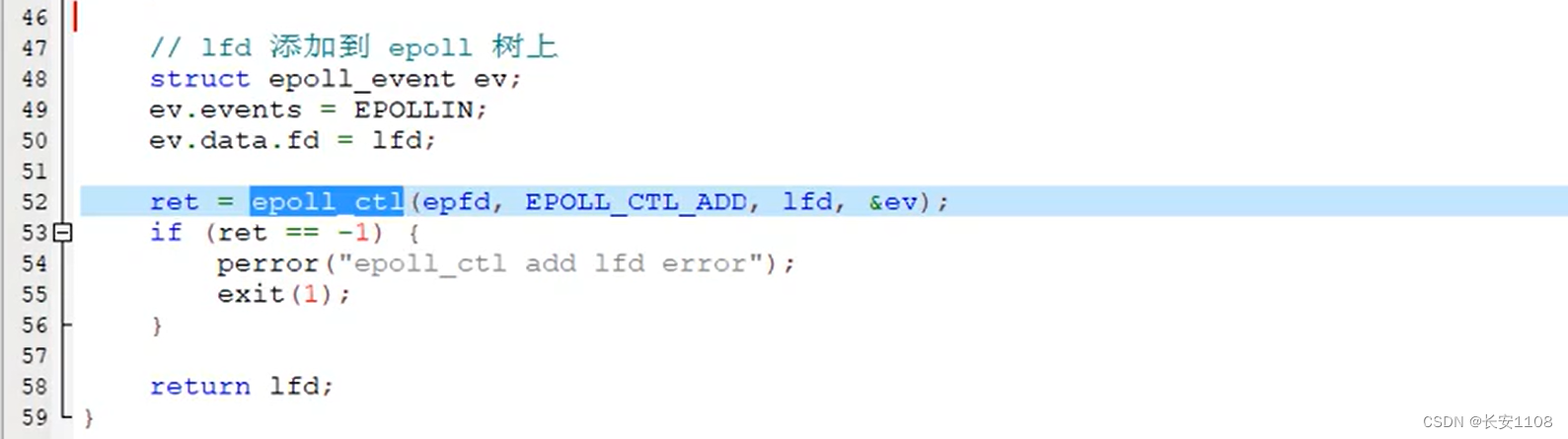
即,根据传入进来的port(端口)、epfd(epoll树根)等参数,进行lfd的创建以及上树
包括,创建socket、创建服务器地址结构、设置端口复用、给lfd绑定地址、设置监听上限、将lfd上树,预监听其读事件。
最后返回lfd
epoll_run函数
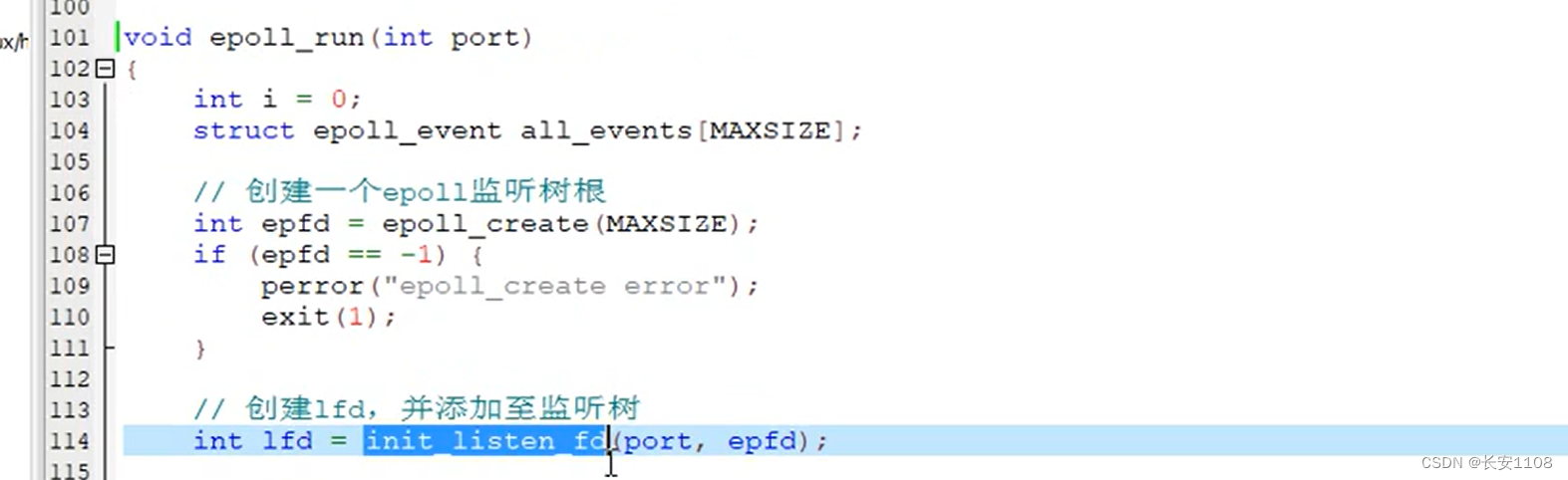
根据传入的port,首先,创建一个epoll_event数组,用于后续的epoll_wait监听时返回套接字数组。创建epoll监听树树根,之后传入init_listen_fd函数,创建监听套接字lfd,并将其上树
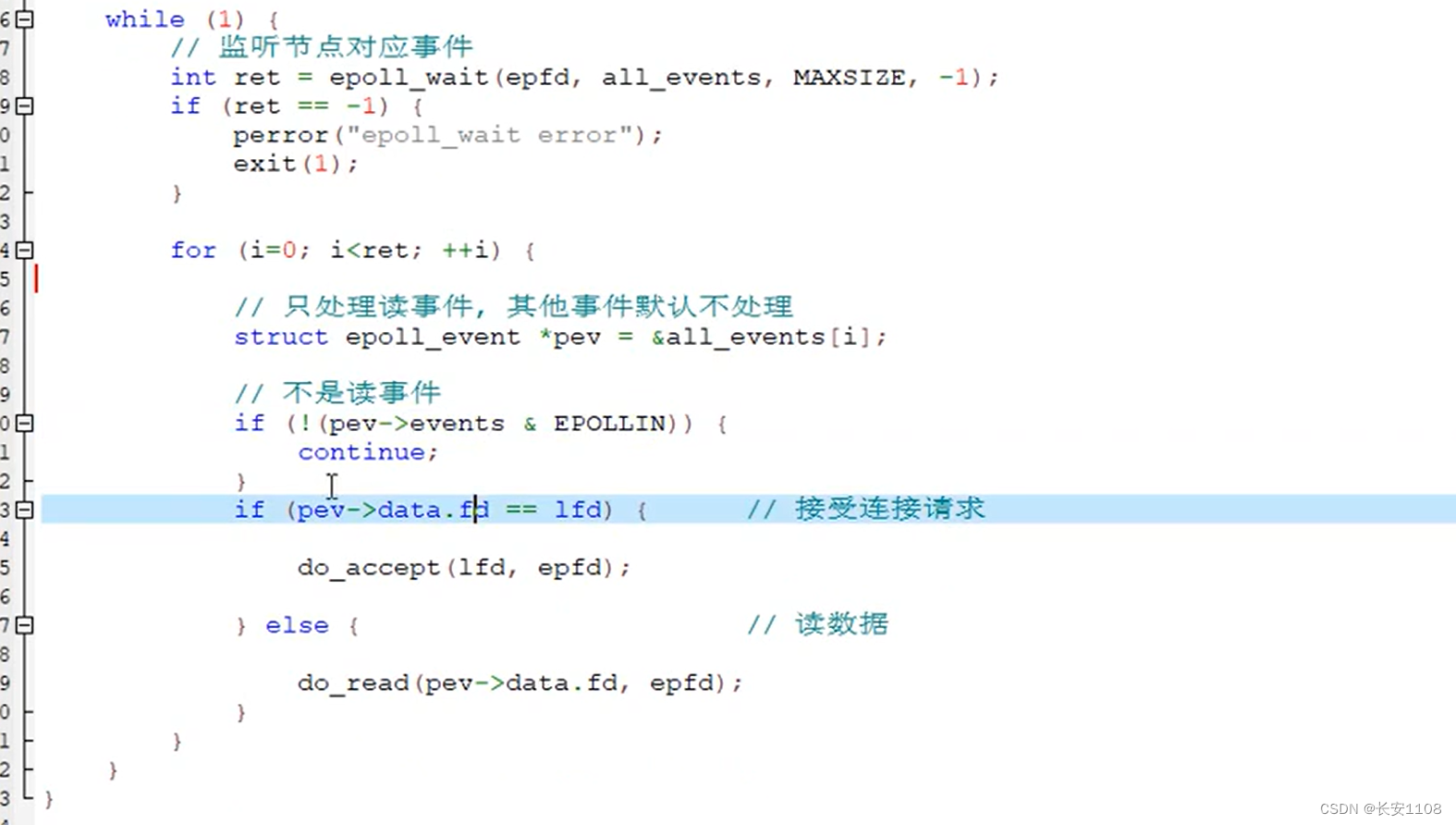
在lfd上树之后,我们就可以开始监听了
while循环内,使用epoll_wait开始监听,将监听结果返回到all_events数组。
之后拿到返回值,就是all_events数组的有效元素个数,也是其循环上限,
在循环内,我们默认只处理服务器的读事件(也就是只处理接收请求),其他事件不处理
将其元素挨个取出,转为指针,如果不是事件,直接continue,如果是,进行后续代码:
读事件又分为是lfd收到数据还是其他cfd受到数据:
如果是lfd,进行accept进行新的cfd创建与连接
如果是cfd,那么进行数据的读取
do_accept、do_read函数也是封装的函数
do_accept函数
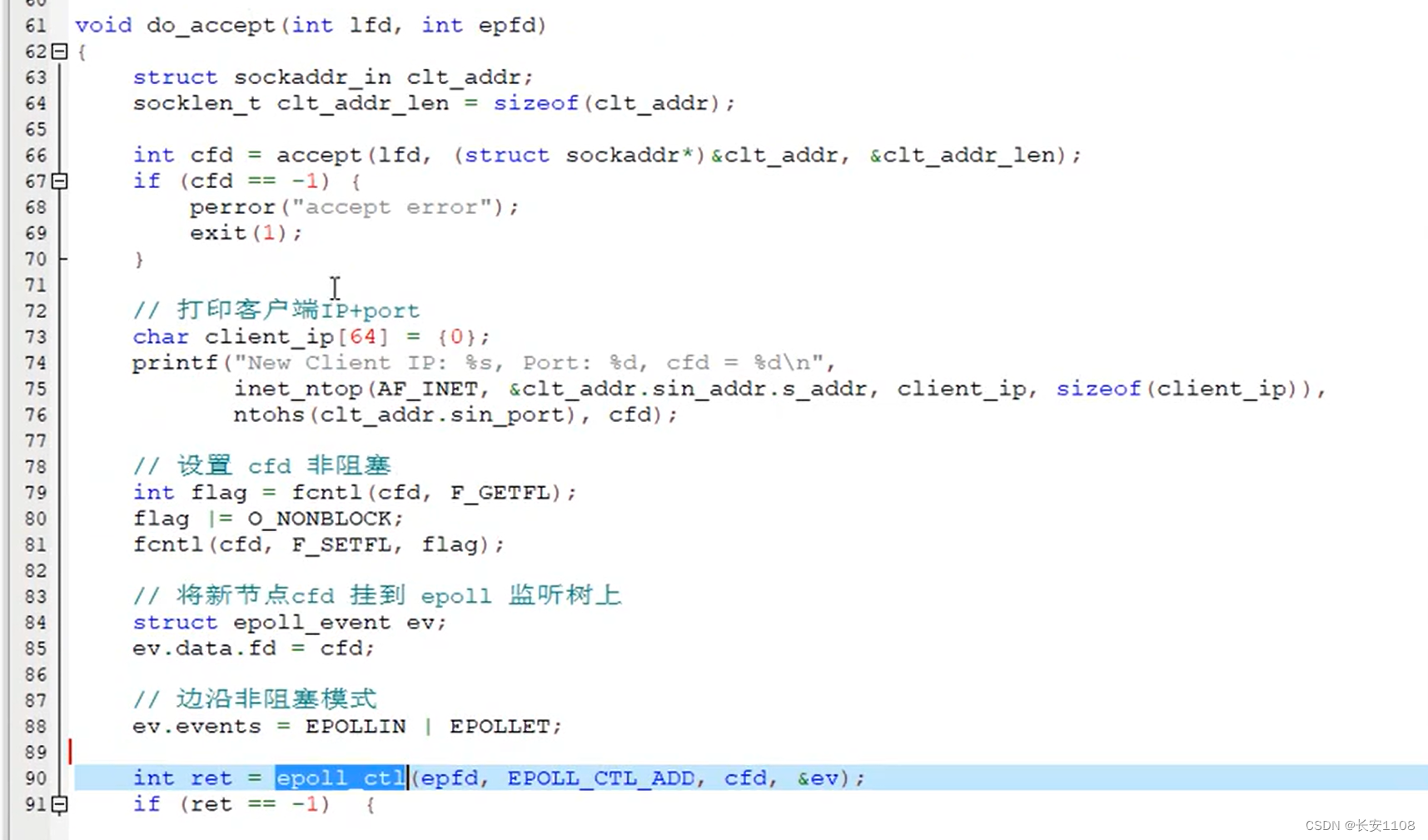
根据传入进来的lfd,和epoll的树根,进行新的cfd的创建以及相关设置
首先,调用accept函数,进行新的cfd的创建,返回新的cfd,
之后,将其设置为非阻塞
之后设置ET模式,这是经典的ET+非阻塞,是高效模式
最后将其挂上树,进行监听
do_read函数
内容
补充:http中的getline函数
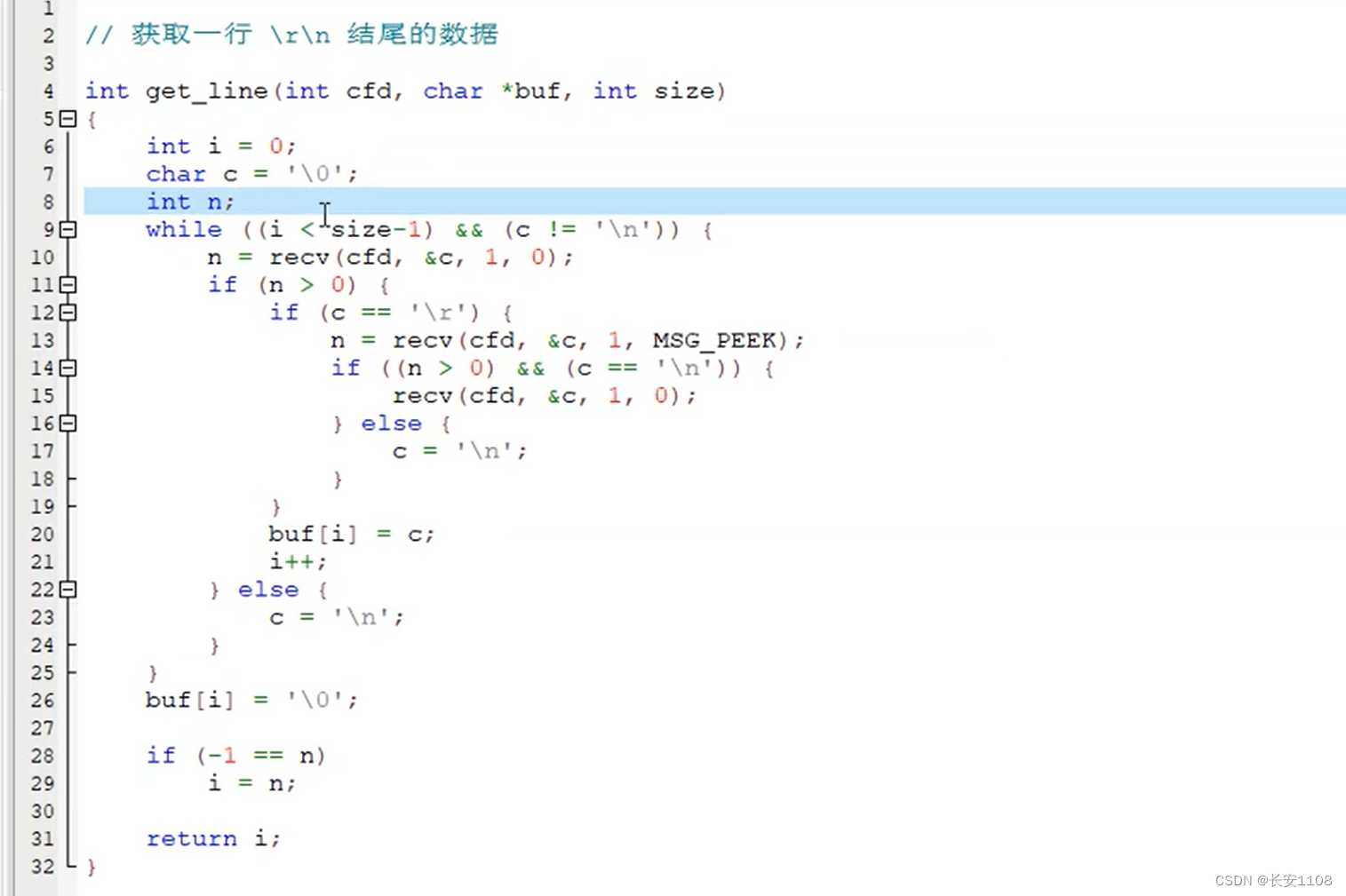
参数:第一个是表示从cfd文件描述符中读,第二个是传出参数,表示读到的数据,第三个是传出参数对应实参的开辟空间大小,使用时,直接传sizeof(第二个实参)
其中,recv的第四个参数如果是0,那么就是真实的从缓冲区拿数据读进来
而如果其第四个参数是MSG_PEEK,那么就是拷贝读取,并不会动缓冲区中的数据
上图中的所有recv,每次都是只读取一个字节
返回值为所读取到的字节数,将数据读进传出参数buf中
详解do_read函数(借助http协议进行通信的具体数据读写过程)
首先实现单文件请求
思路

1、首先使用封装的getline,读收到的http协议的请求行。
2、然后对其进行拆分
3、之后判断文件是否存在,使用stat()函数,如下:
该函数传入文件路径,以及一个传出参数变量,即可通过返回值,判断文件是否存在,而这里传路径时,直接将拆分完的路径传入即可,会因为服务器已经在main函数时被chdir切换为了对应的目录,而浏览器也是以服务器启动时提供的路径为参考,所以,可以直接传入
4、判断传来的路径是文件还是目录(若是文件进行后续操作,若是目录,则将目录信息发送回去,此处不做研究)
5、使用open函数,打开文件,并将其内容读取到
6、首先封装http应答的数据包的协议头:
主要包含两部分,一个是第一行的版本号、状态码、状态描述
另一个是附加信息中的“文件类型”
7、将数据封装到协议头的下面,最终生成http应答数据包,将其发送回浏览器
代码实现(读取请求+发送应答(协议头+数据正文))
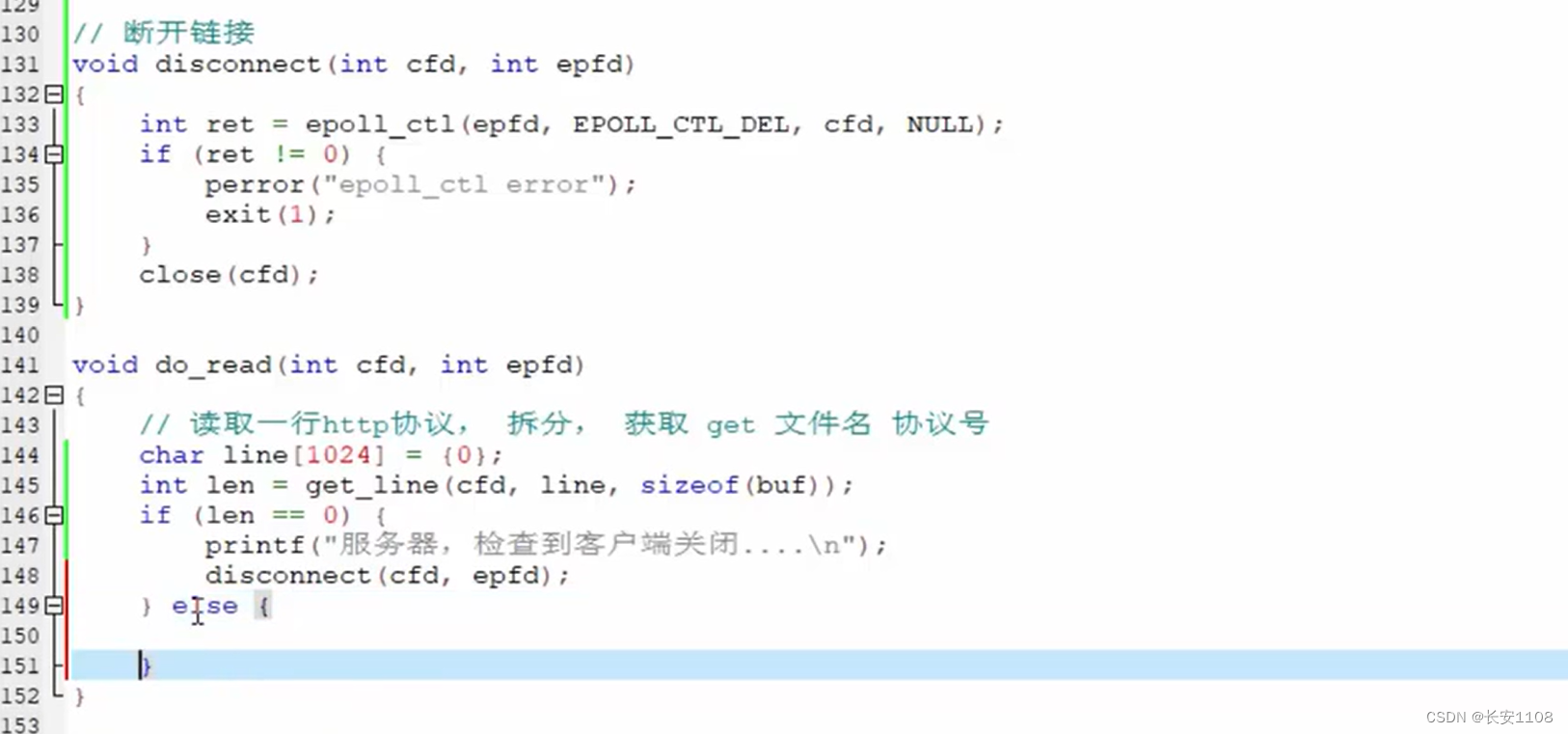
更正:145行,sizeof内应该是line,而不是buf
因为我们会频繁用到将某个cfd,关闭,且下树的操作,所以,可以将该操作封装为一个函数,如上图中的disconnect函数
之后,对do_read进行实现,首先,创建并初始化一个字符数组
之后,get_line读取数据,传入“传出参数”line,拿到数据
之后,对返回值进行判断,如果返回值为0,表示是对端关闭,所以,我们也进行disconnect操作
而如果不是0,则要进行数据的拆分了,现在在line数组中的是“GET ./hello.c HTTP/1.1”,即是由三个字符串组成的字符数组,接下来是拆分这三个字符串:
使用sscanf函数: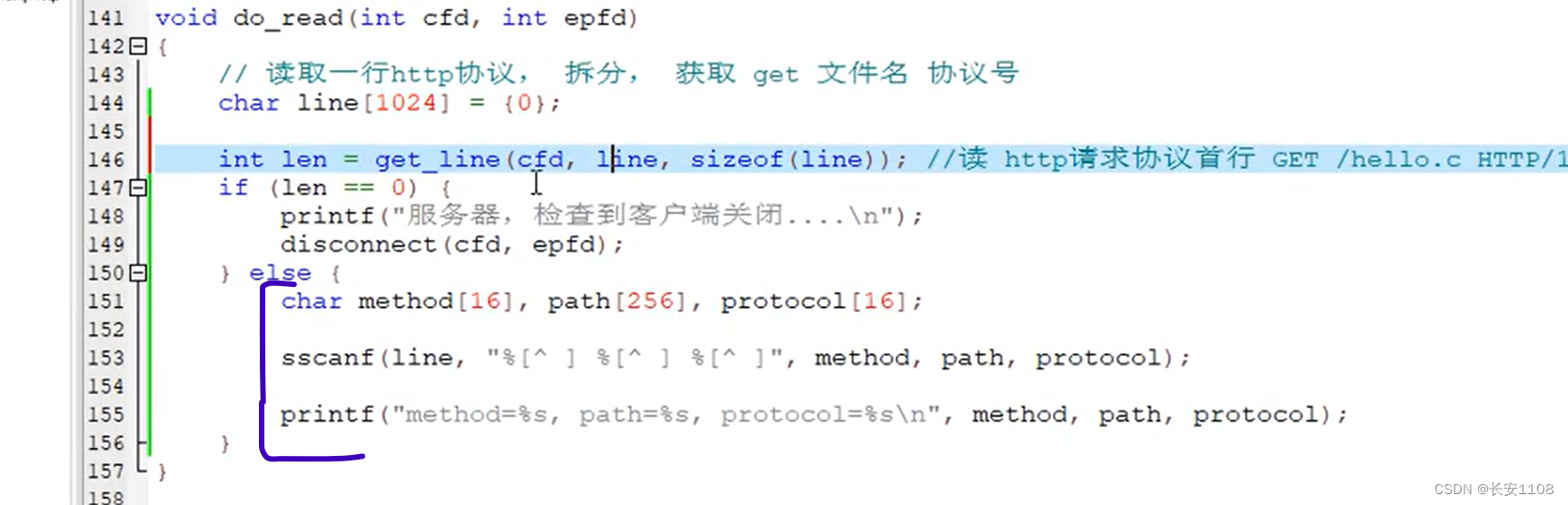
首先定义三个字符数组,分别用于存储拆分后的结果
之后,调用sscanf函数,第一个参数传入要拆分的对象,第二个参数需要传入格式说明符(如%s,%d等),这里我们传入一个正则表达式,大概功能与“%s %s %s”差不多,注意要%s之间是空格,不可忽略

之后: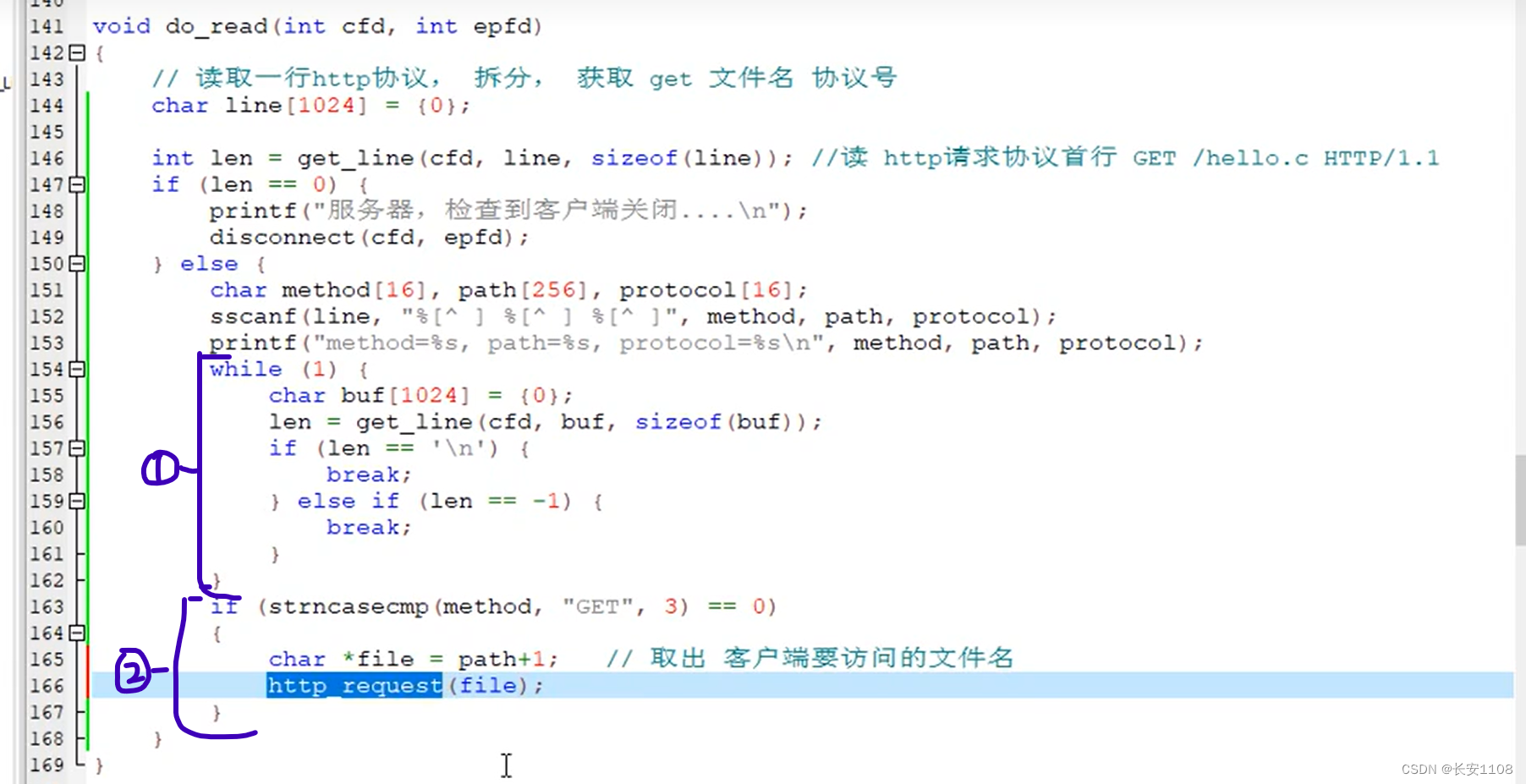
对于图中的第一部分,作用是:读取第一行之后的附加内容,不让其存留于缓冲区中,防止其影响下一次的读取(因为ET模式对于剩余的数据会在缓冲区等待我们主动读取或者下一次数据推送)。(因为我们这里心知肚明收到的肯定是GET请求,所以,并没有判断是否读到了附加内容结束,因为对于不是GET的请求,将附加内容读掉之后,接下来的“数据正文”是不可以直接丢掉的,应该存起来留用)
图中,如果len==‘\n’,本来是想表示读到了回车,也就是空行的下一行会自带换行回车,本意是想判断是否读完了整个附加数据(即读到了空行的下一行),但是这里的判断操作有点迷,到时候可视具体情况来定
对于第二部分,是将读到的第一个字符串与“GET”对比,查看是否相同,即查看第一个字符串是否是GET,
在linux中:
使用strncasecmp,该方法是将第一个参数与第二个参数相比看是否相同,且忽略大小写,且可以通过第三个参数指定比较前多少个字符
而strcasecmp,没有n,该方法也是比较第一个参数与第二个参数是否相同,忽略大小写,但是无法指定比较前多少个字符
(若此时用的是string,那么可以使用c_str()方法,将其转为char指针类型,再进行函数比较,或者将string每个字符统一转为大写,再与“GET”比较)
win中忽略大小写的字符指针之间的比较的函数是:stricmp()
上图中,比较读到的第一个字符串,与“GET”,且只比较前3个字符,这里是担心因为’\0’而误判,实际上这两个都被补了‘\0’,但是只比较前三个会无需考虑是否有’\0’。
而如果确实是GET的话,返回值为0,如果返回0,那么就要进行相关GET的操作了,字符指针=path+1,因为path第一个字符是‘/’,他并不是文件名的一部分,所以,跳过,直接+1,从第二个字符读取
然后封装一个函数,将文件名传入,进行相关的处理
之后对于http_request()函数: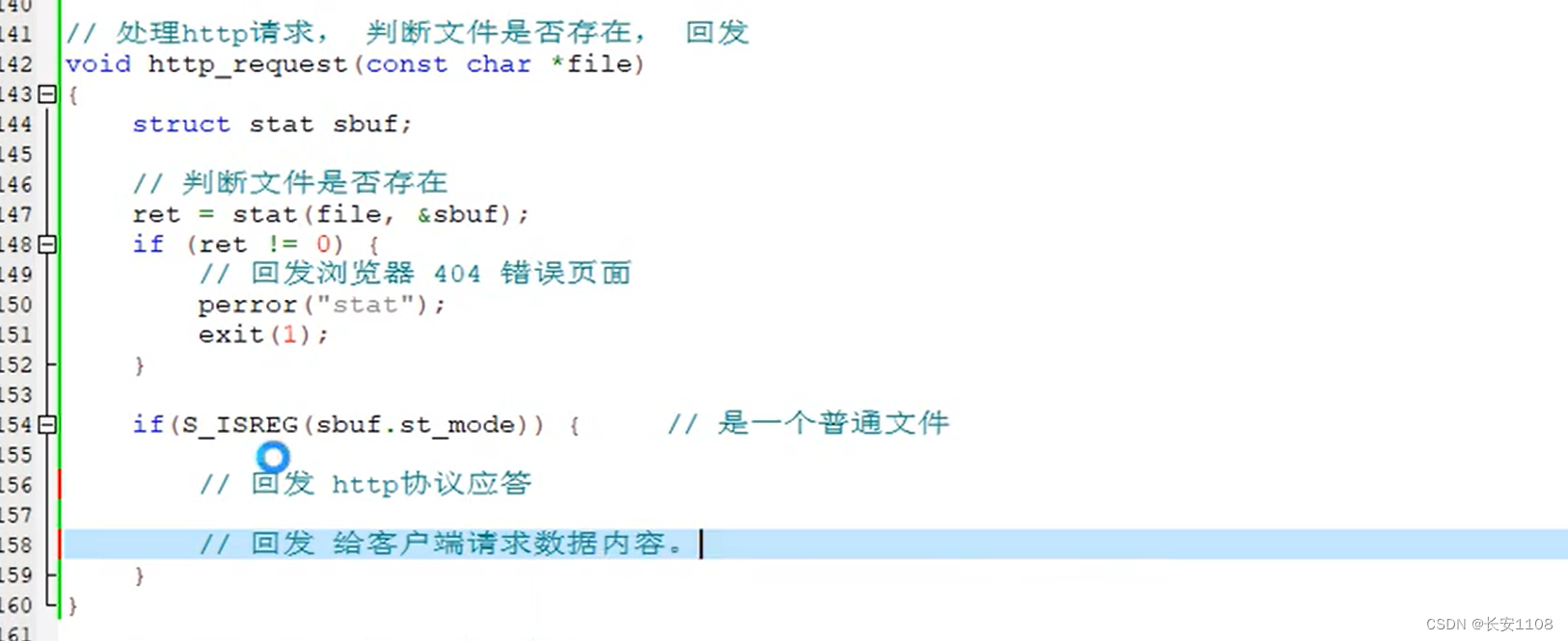
我们已经确定了请求是GET,接下来就是对GET做相关的操作,对于GET请求,我们要判断文件是否存在,
判断文件是否存在,使用stat方法,使用方法如上图,先创建一个结构体,struct stat类型的结构体,之后,调用stat方法,第一个参数:文件名,第二个参数:结构体地址(该函数使用时要保证服务器当前工作目录切换到了要搜索文件所在的目录)
如果返回值不是0,那么代表文件不存在,这时要回发给浏览器404错误页面,而服务器的代码可以有一个perror,来进行异常显示,至于要不要exit退出服务器,并不一定,根据具体需求。
前面都没有问题的话,说明文件存在,这里,就要判断其是文件还是文件夹,使用stat自带的宏来判断:
S_ISREG(结构体变量.st_mode),如果为真,则是文件,如果S_ISDIR(结构体变量.st_mode)为真,则是文件夹(或者说是文件目录)
如果是文件,那么接下来的操作就是
1、回发http应答
2、回发请求的数据内容
对于我们封装的回发函数(send_respond):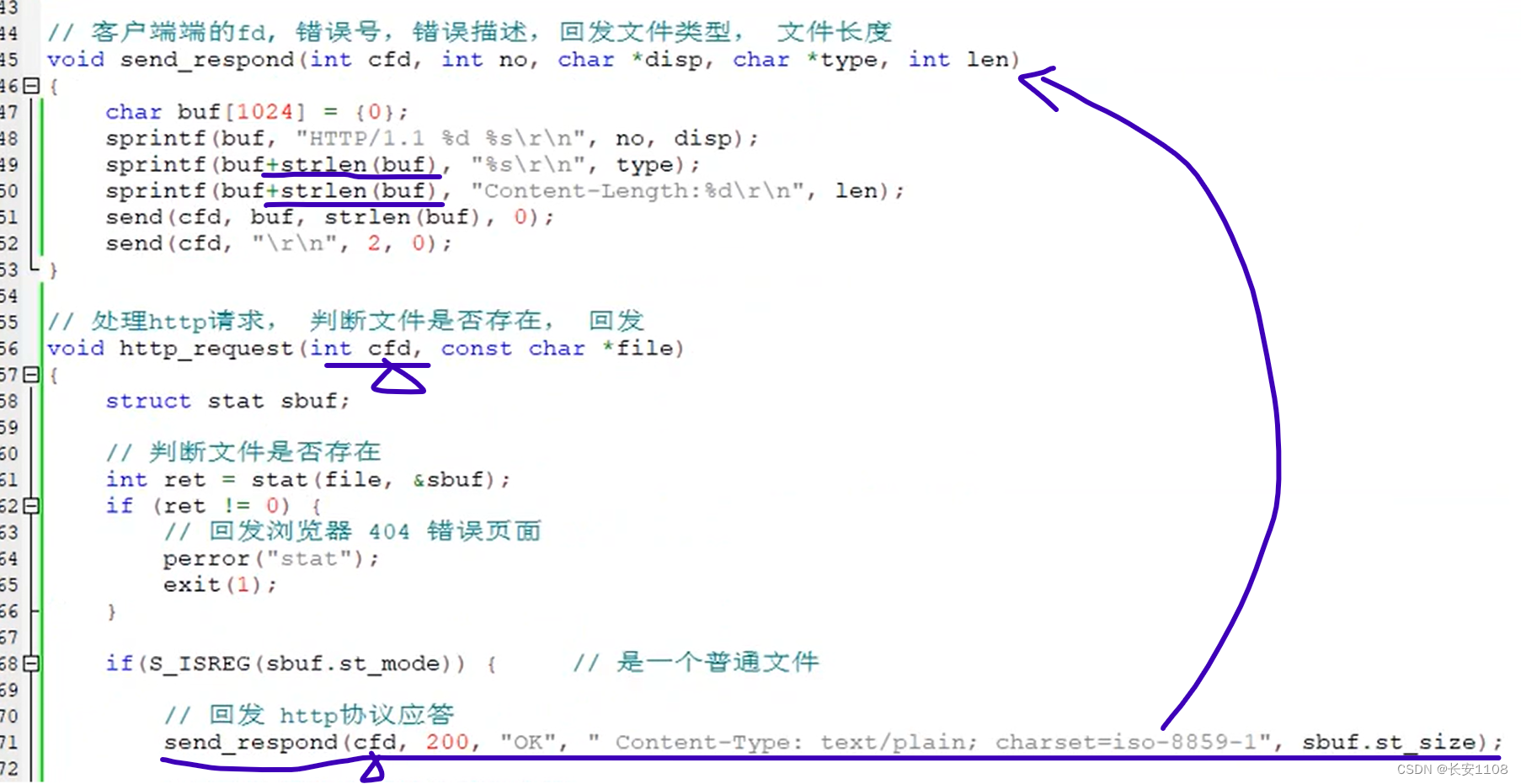
这里我们应该清楚,所谓协议,实际上就是一堆字符串,他按照一定的格式,将有效数据糅合进一堆字符串中,所以,我们回发时,也是,主要进行字符串的拼接操作
首先,对于参数,我们需要:与浏览器通信的cfd(因为我们服务器还是使用socket的epoll服务器),状态码(用no表示),状态码描述(disp指针接收),文件类型(即附加内容中的第四行,这是必不可少的),文件长度
在调用时,将参数传入(这里注意,此前http_request并没有接收cfd,这里在此处更改,写代码的时候注意)
之后,在send_respond中:
首先定义一个字符串buf,初始化为0
之后使用sprintf,将字符串拼接到buf中,使用方法见上图。
而想要再次拼接,且在buf原有的内容后面追加的话,继续调用sprintf,但是第一个参数传buf+strlen(buf)
注意,在http中的换行是\r\n
将所有内容使用send发过去之后,还要将第9行的/r/n发回去
至此,GET的协议应答就发送完了
而对于,buf+srtlen(buf)的可行性: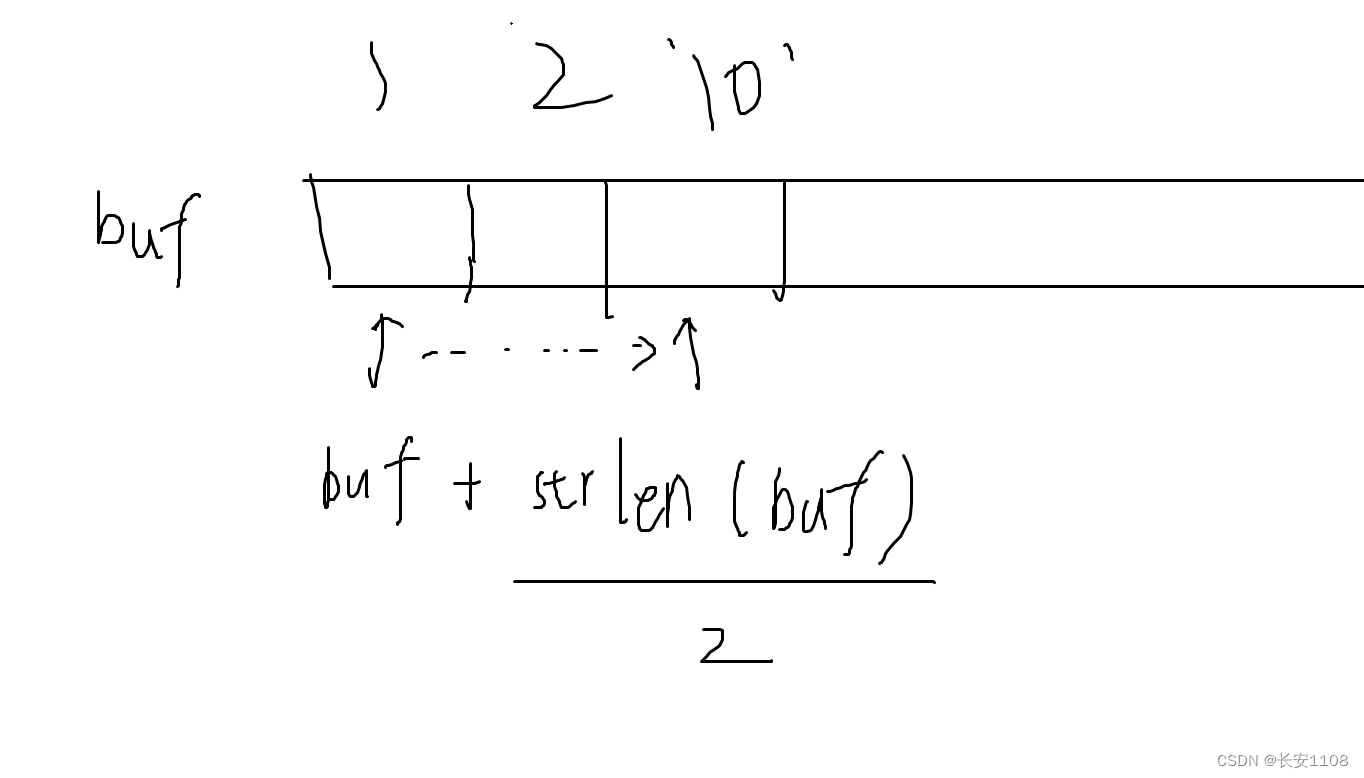
strlen会计算字符串的字符个数,且不计算最后的\0,所以,不管最后有没有\0,buf+strlen(buf),都会来到有效数据的下一个位置,
如果有\0,那么就覆盖其\0,毕竟我们都想要追加内容,\0作为结束符,自然要被覆盖,且必须被覆盖,
如果没有,自然在后面接着写数据即可
发送完了协议应答,就要发送下面的数据正文了: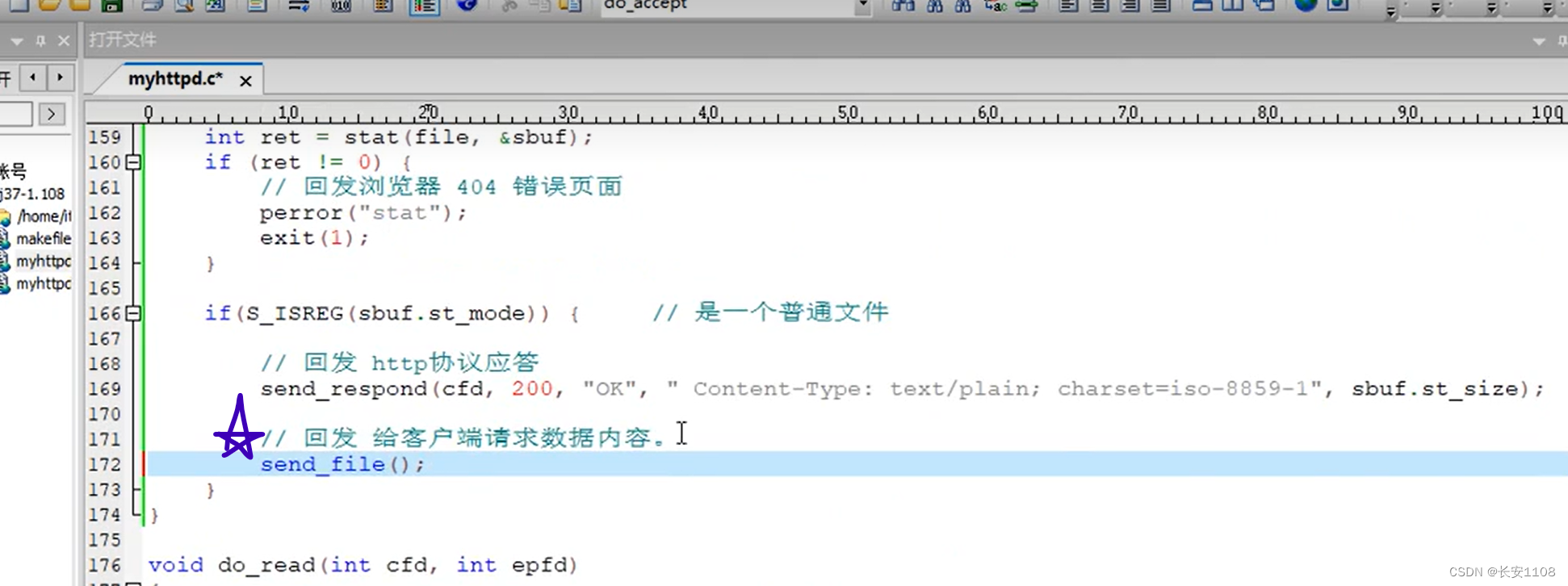
接上面,将http应答协议头发回去之后,就该发浏览器请求的数据正文了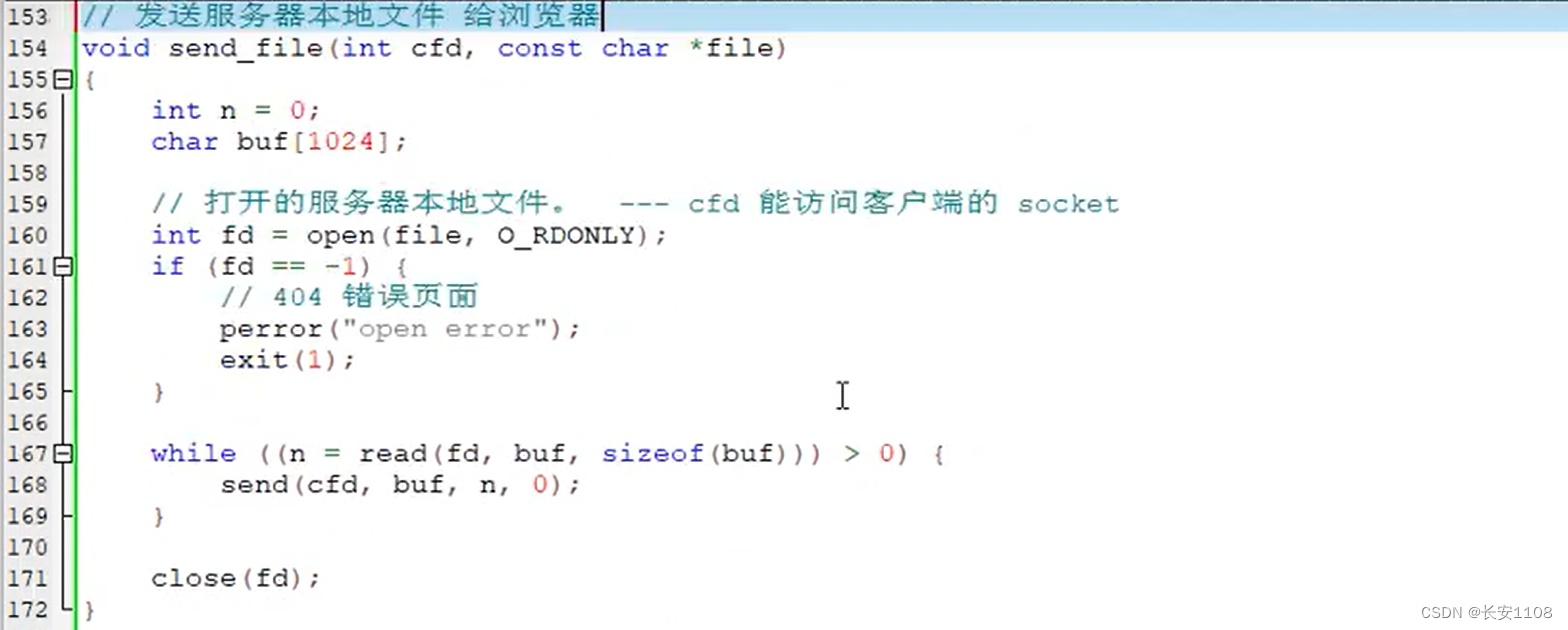
打开指定的本地文件,用fd接收(注意这里的fd是代表本地文件,而之前的cfd是通信文件描述符,即套接字,二者不要混淆),之后使用read从打开的本地文件中读数据给buf,然后再使用send将buf中的数据写给cfd
补充:错误解决
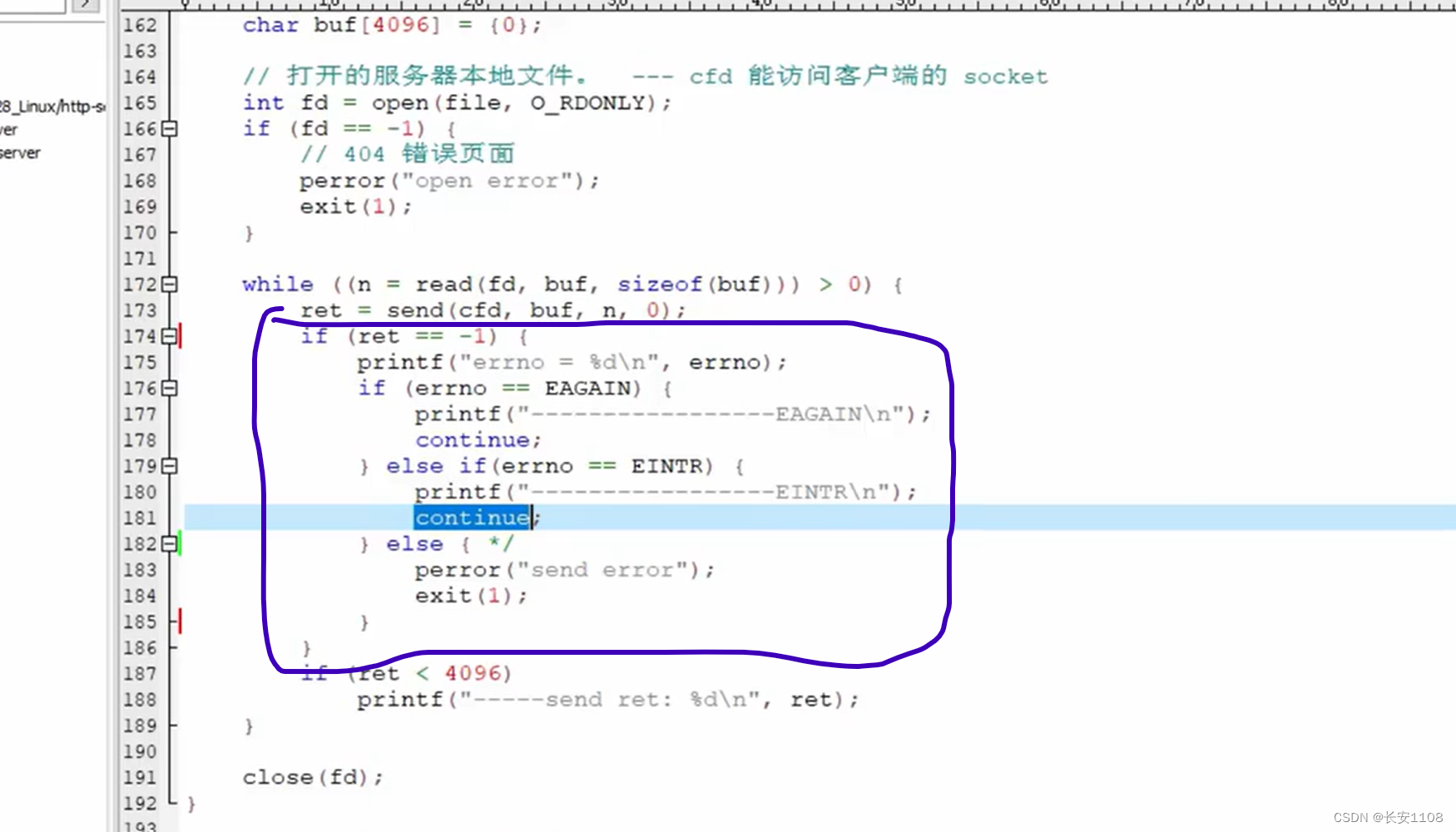
当我们想要发生的数据正文是其他非文本文件时,我们要采用二进制读写文件的方式,而linux中,read、send都是默认二进制读写,所以直接使用即可。(可将该部分与之前单纯读写文本的代码进行对比,实际上只是在while的send后面加了一些代码)
而上图中圈出来的部分,是对send的特殊处理,当send返回-1,表示出现异常errno,这里需要注意,如果我们接到的异常是EAGAIN、EINTER的话,可以直接忽略他们,因为这些异常是编译器多虑的结果,直接continue即可
补充:正则表达式(简要介绍)
正则表达式,就是专门对字符串进行操作的,他可以表示出你对字符串的任何需求
其中,刚刚的[ ^空格],是匹配除空格之外的任意字符
更多请查看下列网站:
补充:上述代码中用到的函数的原型
strncasecmp

stat

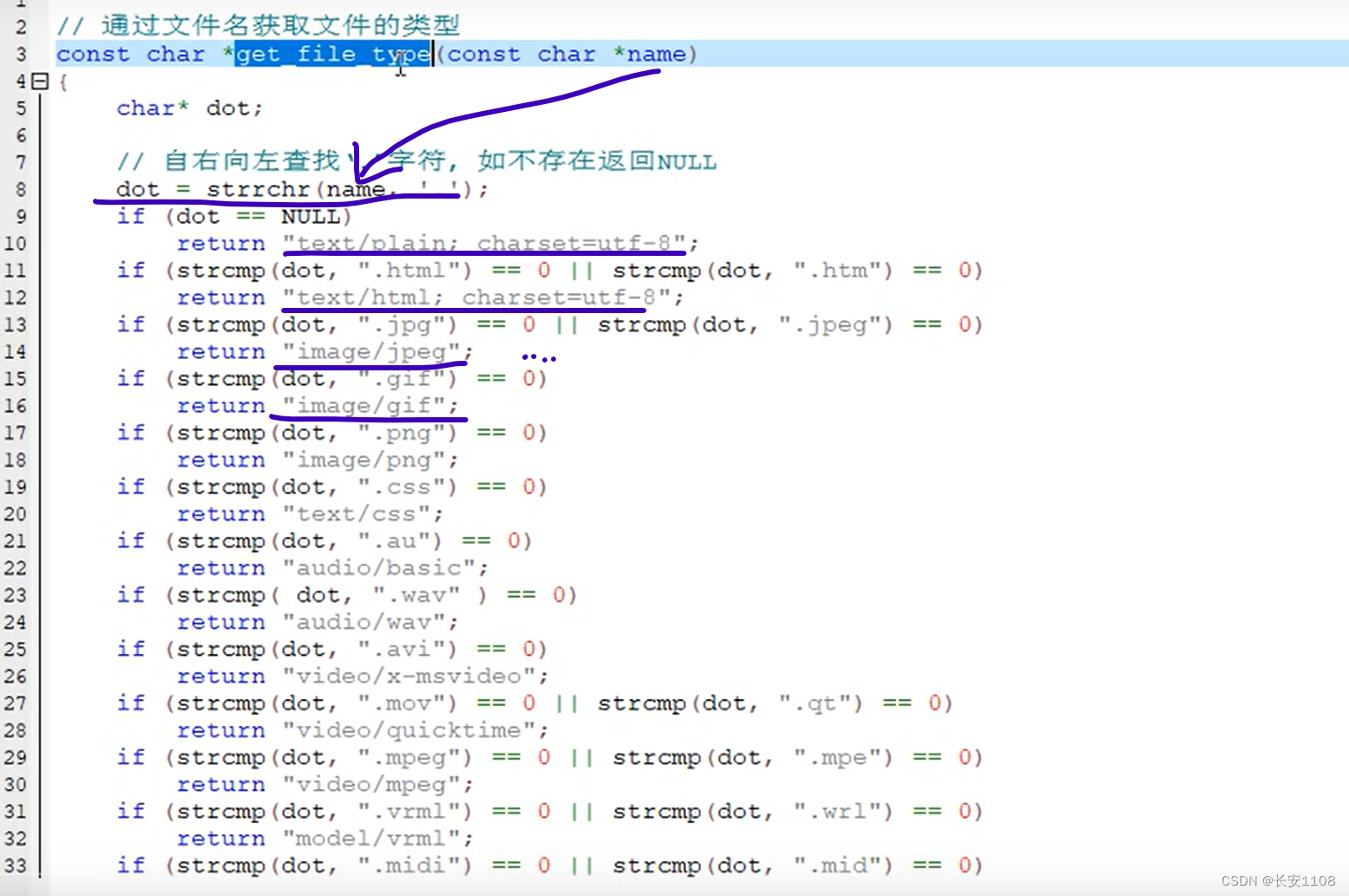
下面是使用stat的宏来判断“使用stat搜索的文件”是文件还是文件夹: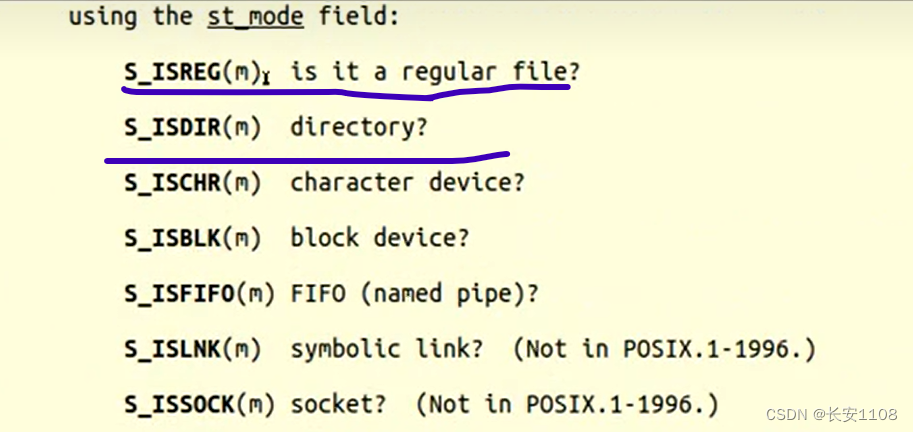
根据文件类型对应其协议应答语句

发送html页面
注意:想要在字符串中发送双引号,要在双引号前加"",表示转义,才会将其双引号当做字符串的内容
这是发送html页面的代码,可以看到,依旧是包含两部分的内容,一个是应答协议头,一个是数据正文,而这里我们也可以得出结论:
对于数据打包,就是在拼接字符串
协议头部分的字符串,说明一些关键信息,说明文件的类型,可以让浏览器拿到数据正文的字符串后,根据服务器提供的类型进行字符串解析,比如,这里协议头部分的字符串说明:“接下来数据正文是一个html类型的数据”,之后,数据正文部分,将html文件的内容字符串拼接起来,拼完之后,统一发送,这样,浏览器就会根据html类型来解析拿到的数据正文部分的字符串
总结:
1、协议头内容、数据正文内容,都是字符串
2、协议头部分拼接完之后统一发送,数据正文拼接完之后统一发送,而不是一部分一部分发(可以一部分一部分发,没有问题,不过还是建议统一发送)
3、浏览器会根据协议头指定的文件类型解析数据正文的字符串内容
4、数据正文内容可以自己手搓字符串,也可以使用文件读写,这时就是二进制的形式了,所以字符串、二进制都可以
5、浏览器与服务器之间的数据读写仍然是通过cfd的,因为仍然是使用socket进行的服务器搭建
目录文件请求
前期知识储备
一、首先明确:
当网址访问的路径到了一个目录停下时,其发送的http协议中的第一行,第二个字符串,是"/“,不管网址的末尾是否带有”/“,其发送给服务器的协议都会有”/"
之后,我们从判断其文件是文件还是文件夹这步开始: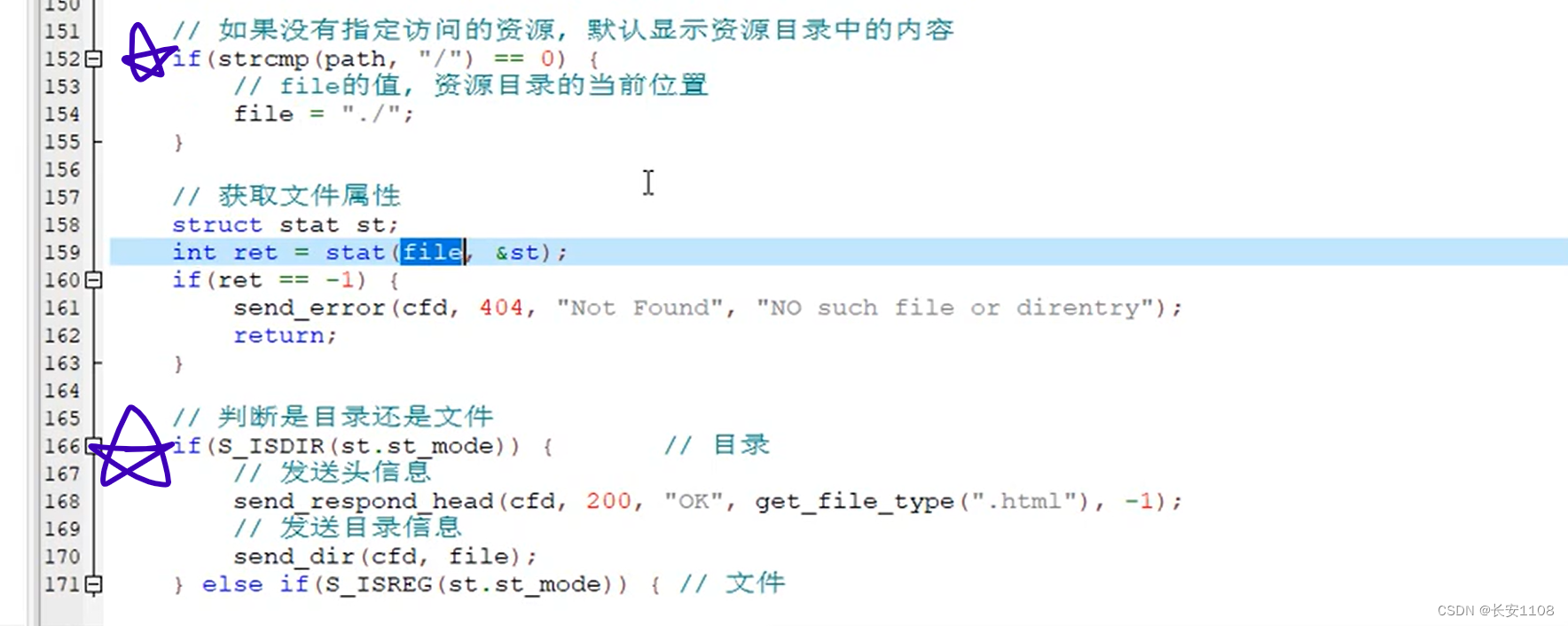
首先,是要对目录路径进行特殊处理,如果当前浏览器的网址访问的是一个文件夹(目录),那么发送给服务器的协议头的第一行的第二个字符串,即指定路径,是“/”,而file=path+1(上图未截到),所以这时file是空字符串,而stat的第一个参数不允许为空,所以,我们要对这种情况进行特殊处理,如果遇到了,将其改成“./”,这样一来,由于服务器启动时被切换工作区了,所以,这里改成这样,代码逻辑不变,且file不为空了
其次,对于如果判断出是文件夹,那么先是发送协议头(这里将协议头和数据正文封装到了两个不同的函数,其实就是将上面的代码放到了两个不同的函数中,没有什么大的不同),协议头中,发送文件类型是html类型,因为浏览器显示时,是html文件将文件内容进行了外观包装。
二、递归遍历目录名: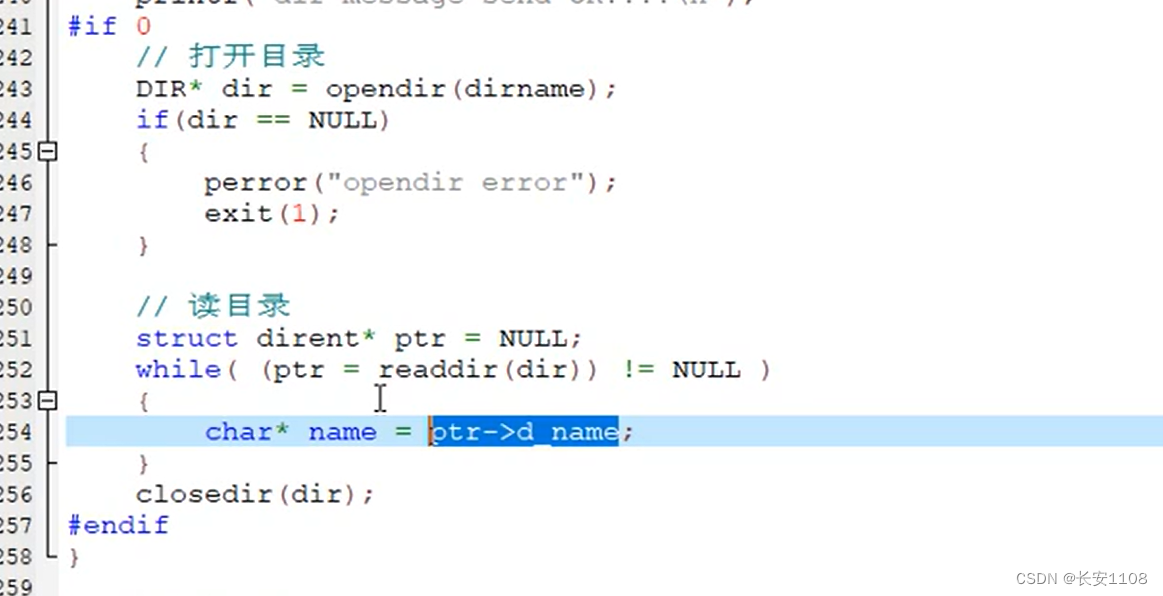
该函数,会将当前目录下的所有目录的名字拿到,包括同级的,以及比当前级更深一级的(因为它是递归调用)
(本项目用不到,因为我们如果访问到一个目录,只会在html中显示当前级的文件/文件夹名,所以,无需递归,我们采取下面的函数)
三、函数:scanfdir()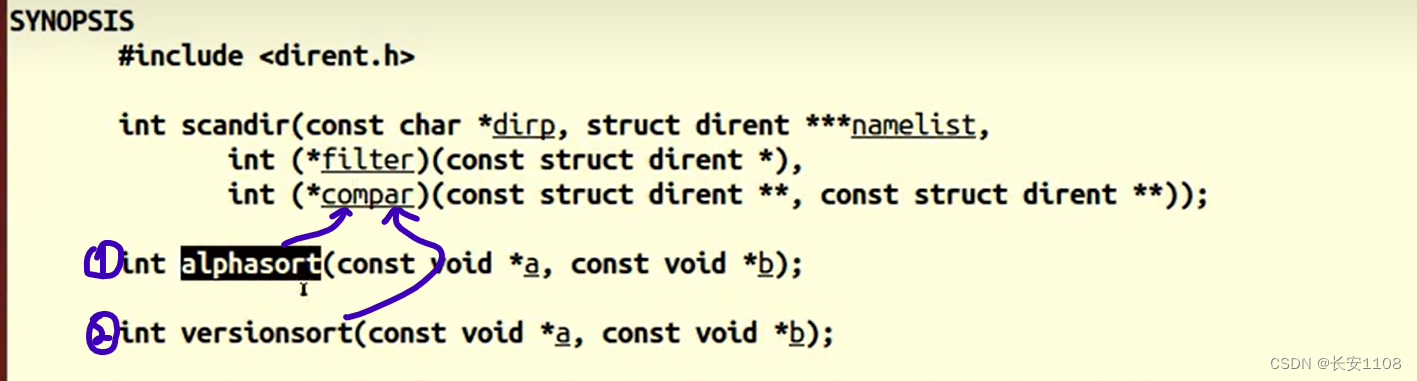
参数介绍:第一个是指定搜索目录,第二个是struct dirent类型的二级指针的地址(即三级指针),第三个参数是过滤器,一般传入NULL,第四个参数是传入一个比较函数,用于指定目录的排序方式,第一个是按字典序(默认第一个)
下面是结构体struct dirent的成员介绍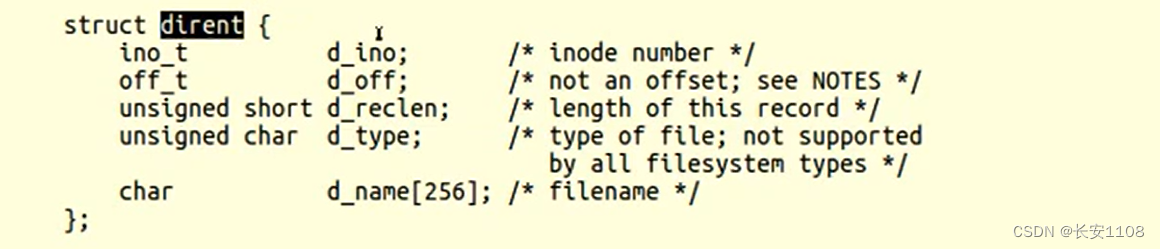
具体使用步骤:
准备一个结构体二级指针,之后传入其地址,他是一个传出参数,所以直接传地址即可,不用其他操作
之后调用scandir函数,拿到返回值,返回值就是有效的数组元素,使用该值可以作为数组的循环上限,之后使用for循环,以及传出参数,就可以拿到目录名
代码实现(浏览器访问目录请求的应答包的数据正文部分)
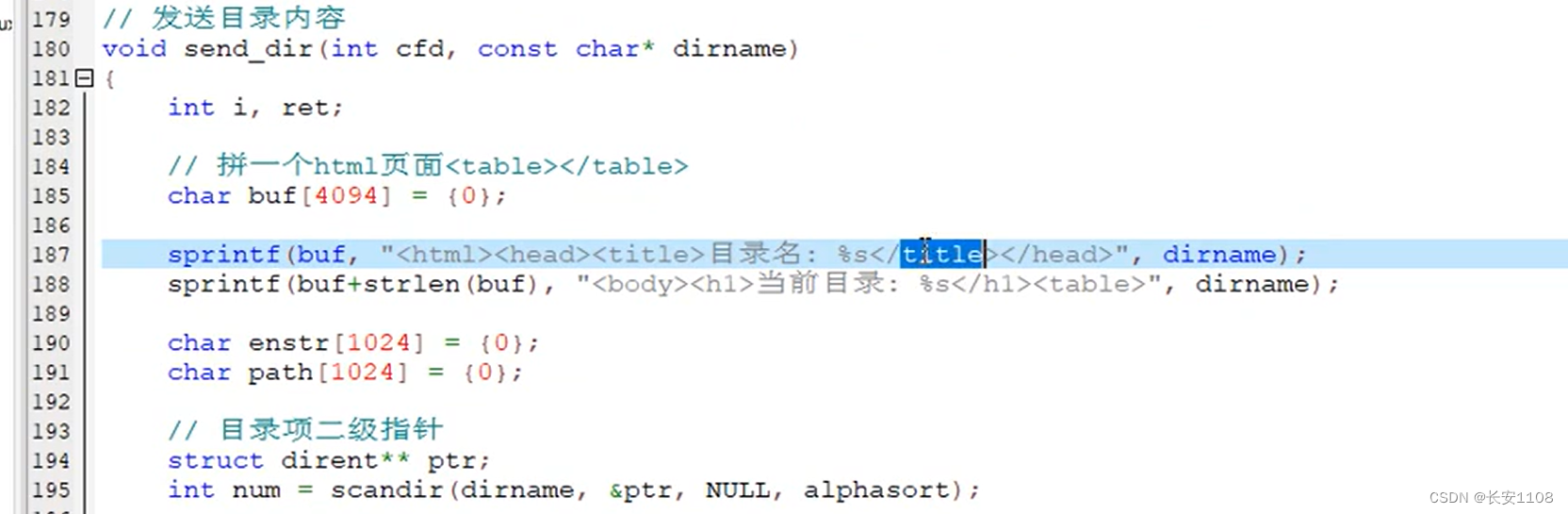
首先,先拼接一下html的title等等头部,且通过scandir拿到目录项(即当前目录的文件名/文件夹名)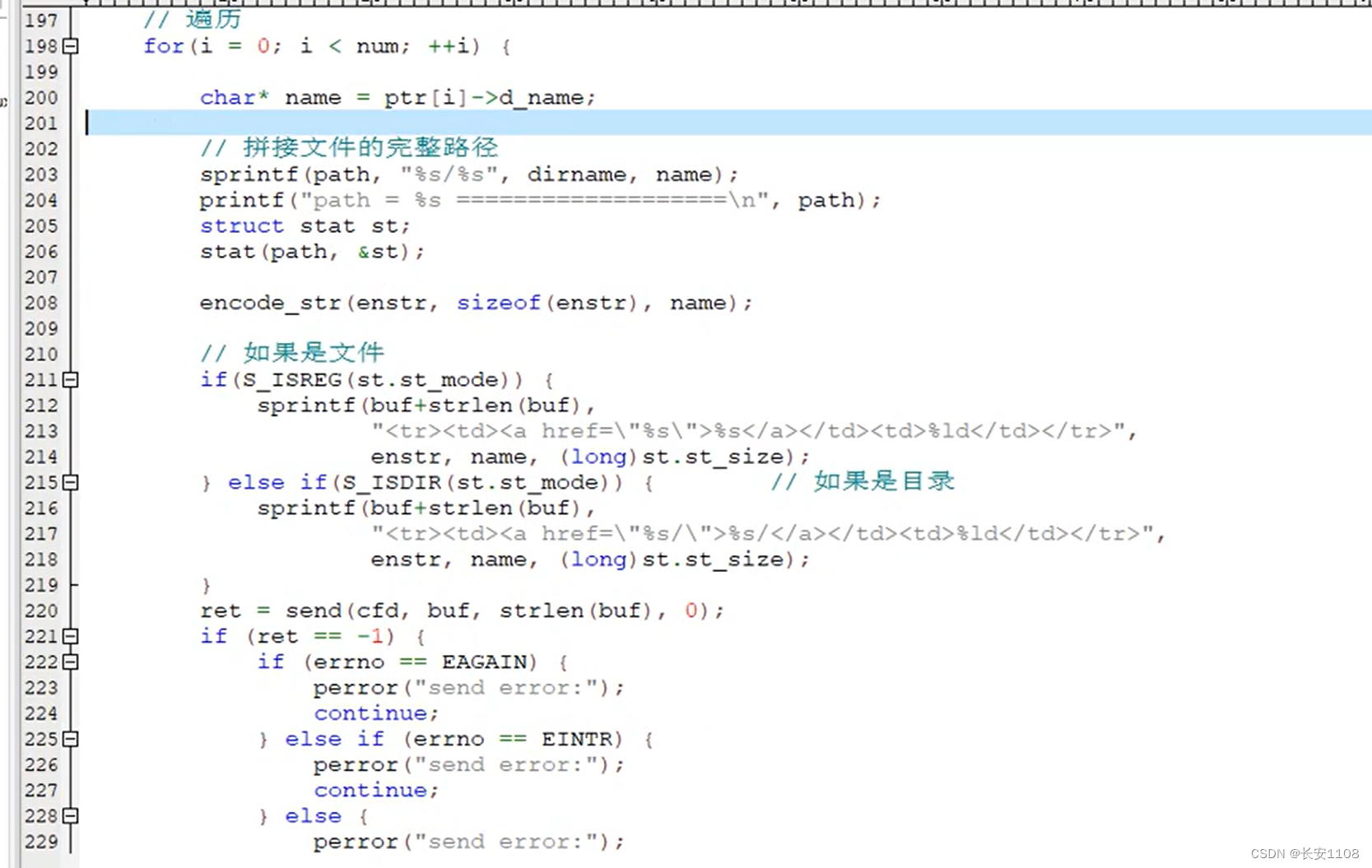
遍历每次拿一个名,然后将其与当前路径拼接成一个完整路径,也就是拿到子目录的路径,
之后判断是文件还是目录,并将其完整路径链接到html上的超链接上
此时,进行一次发送,将buf写回去cfd,并检查返回值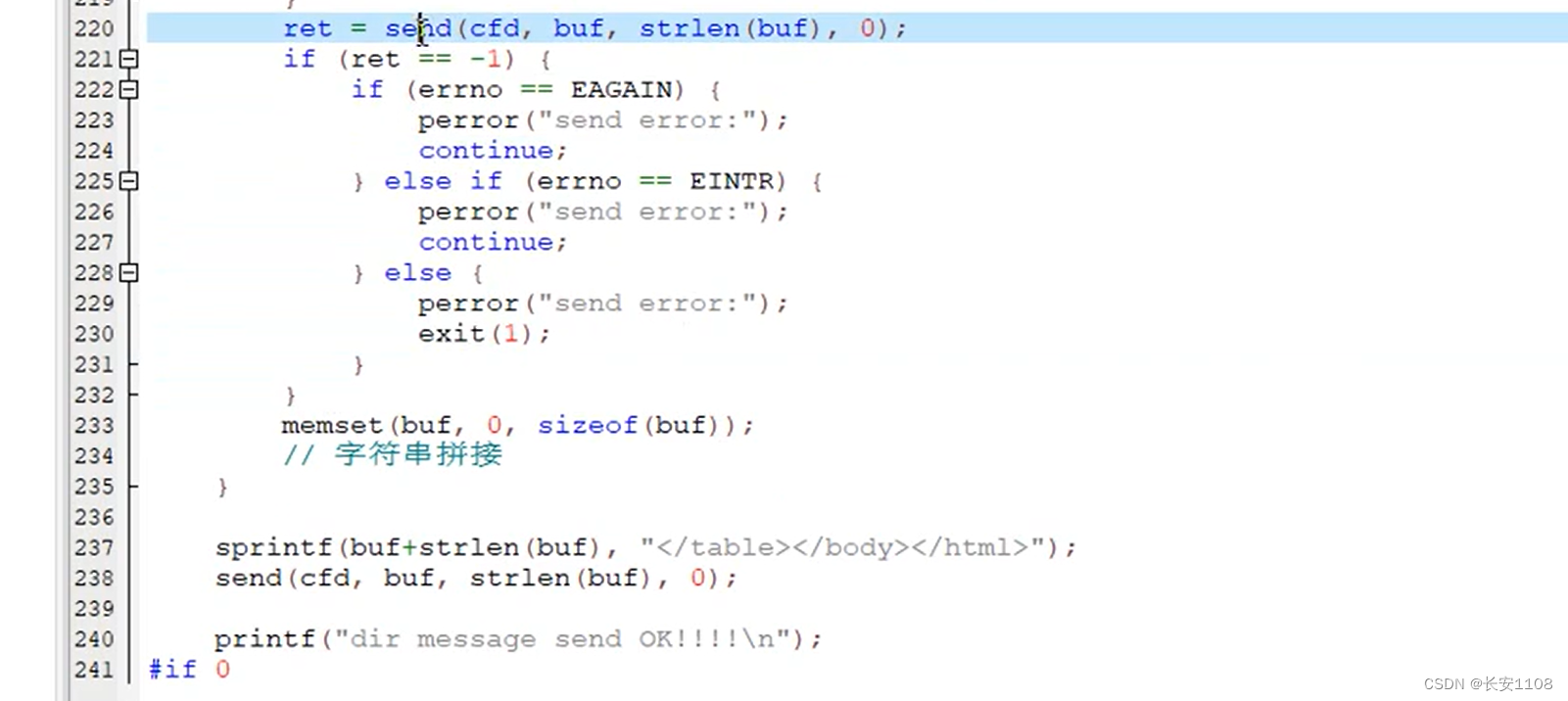
返回值检查完之后,清空buf,我们是想每次for循环,都进行一个新的子目录的处理,因为上面220行就进行了发送,所以,可以直接清空,之后专门进行其他子目录的html代码的发送,最后for循环结束后,再发生末尾的html代码,最后就结束了
开发注意事项
汉字字符编码和解码
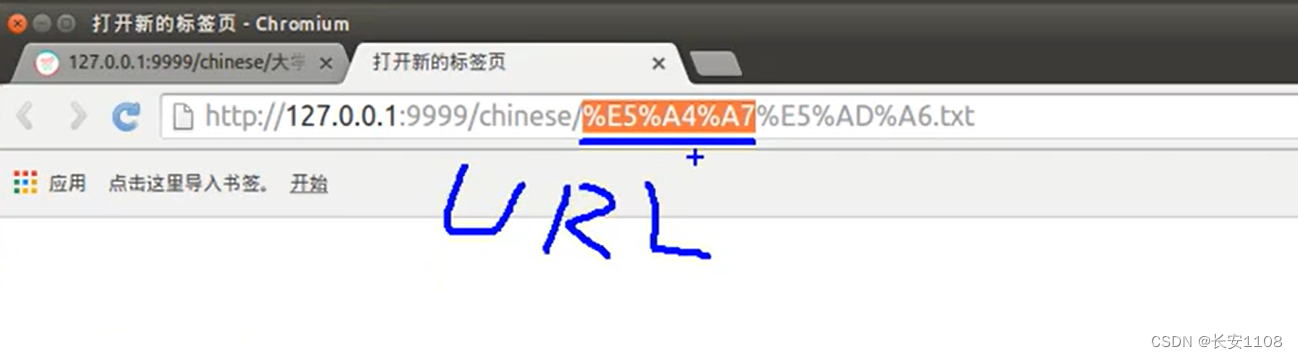
我们在浏览器输入的网址,称为URL,当我们输入127.0.0.1:9999/chinese/大学.txt的时候,如果没有进行任何的设置,他会转为Unicode的格式,如下图,可以查看汉字与Unicode码的对应: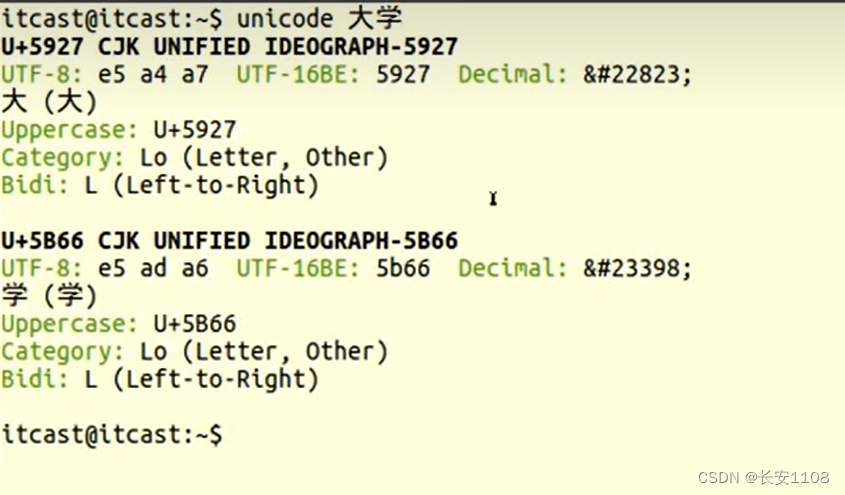
如果没有进行任何的设置,那么http协议封装的就不是“大学”了,而是其所对应的Unicode码,这样的数据传到服务器,服务器无法从目录中找到对应的文件,所以,这里需要解决
结论:
服务器回发给浏览器:编码–从汉字到Unicode–encode
浏览器发送给服务器:解码–从Unicode到汉字–decode
对应到本项目: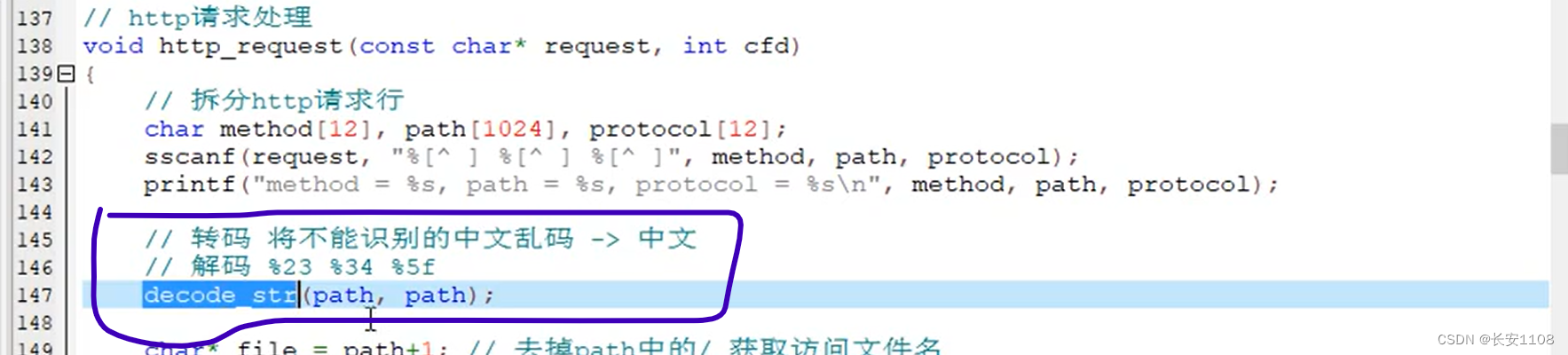
当解析浏览器发来的http协议请求包的第一行之后,就要将path变量进行解码
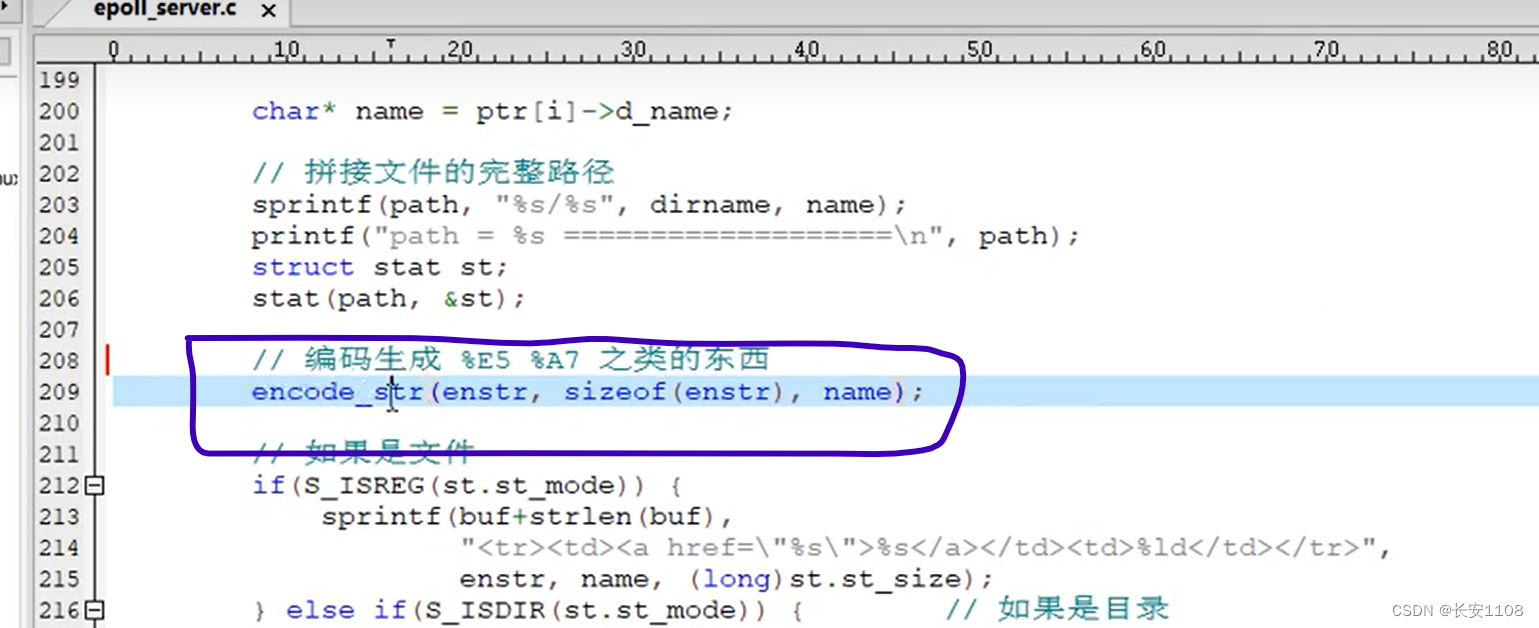
当要发送给浏览器URL之类的内容作为其数据正文时,将其编码为Unicode
具体函数原型: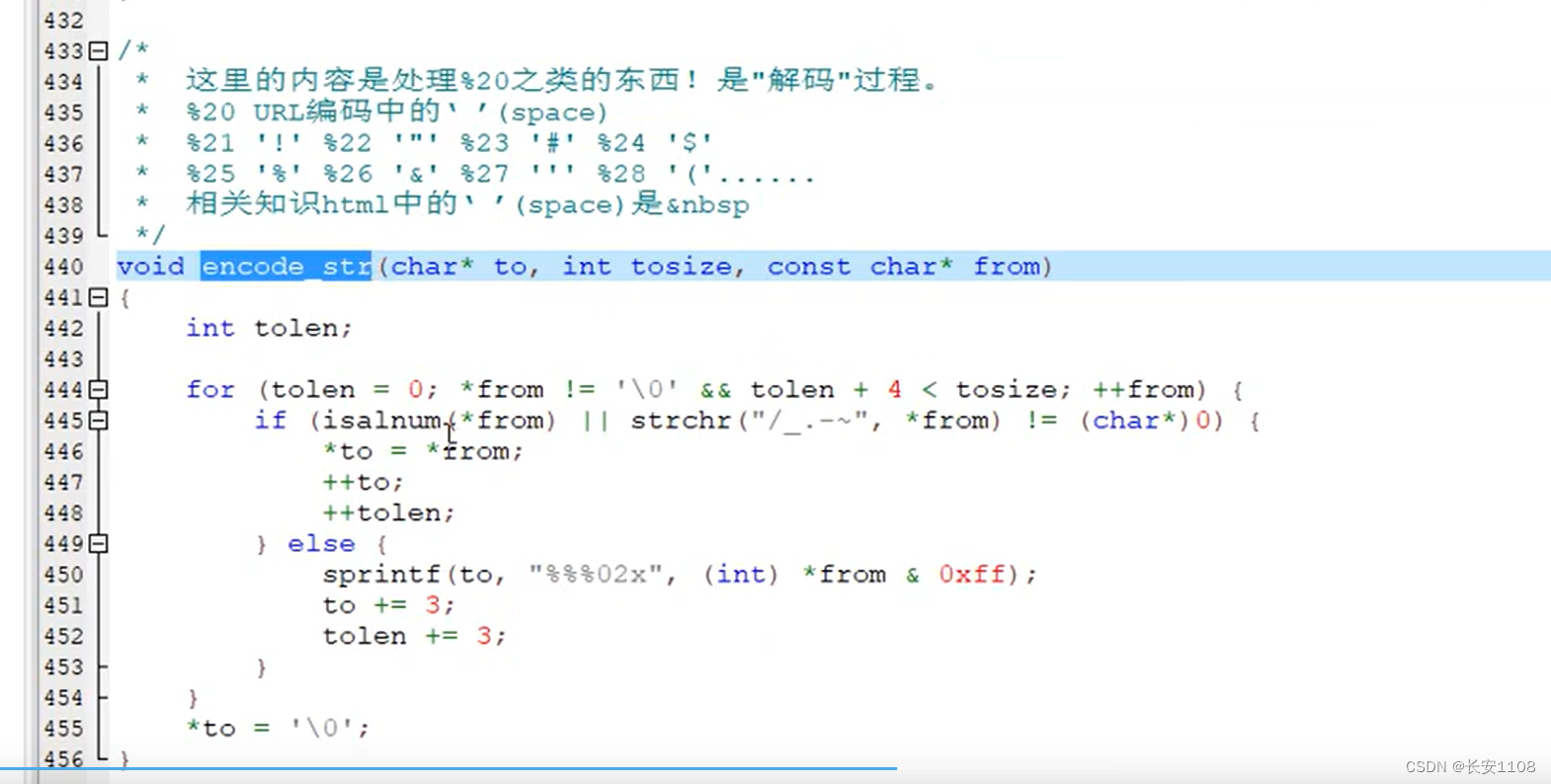
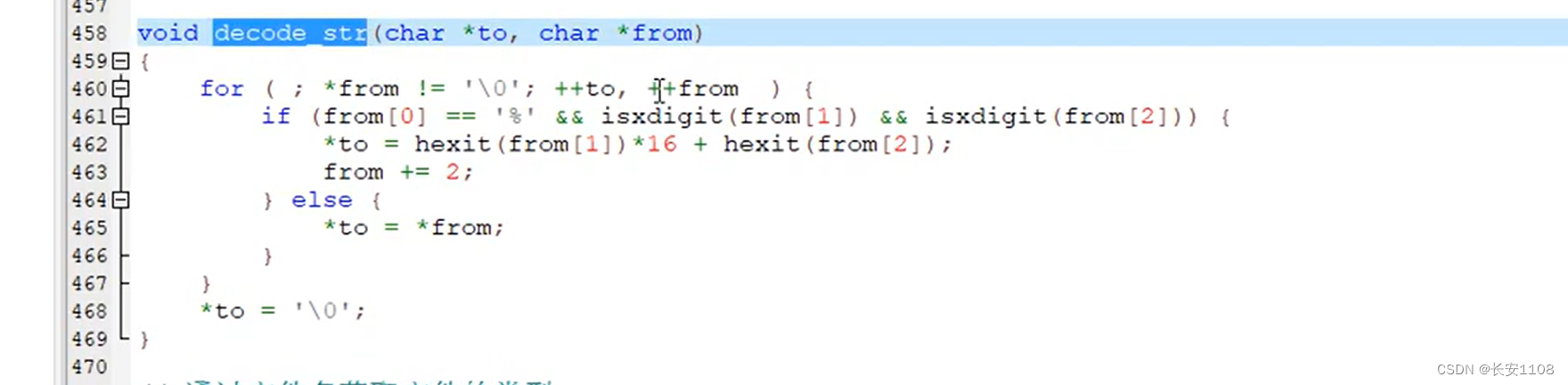
用到的函数: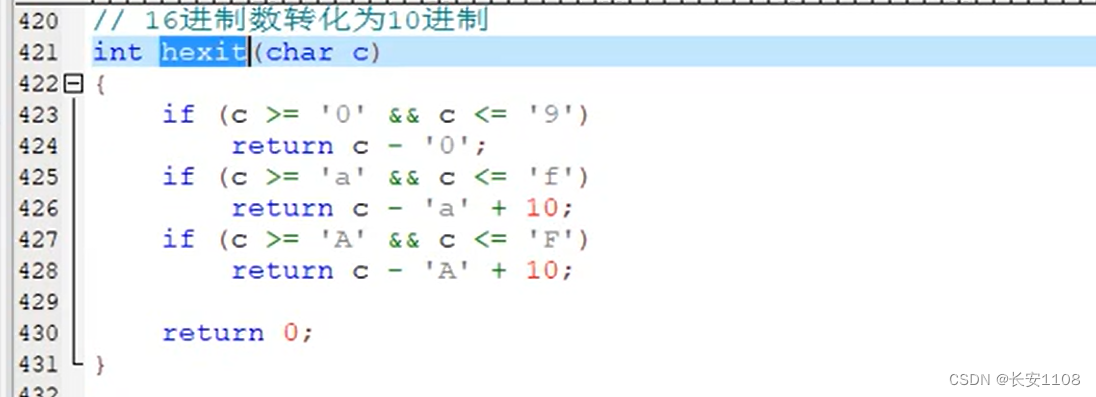
telnet补充

使用telnet,不仅仅可以测出端口号是否可以通讯,还可以模拟浏览器进行http协议的发送,直接在阻塞的窗口内键入http协议的内容,服务器就会回发数据
容错处理

