
阅读量:1
前言:
是根据github上面文档记录的和两个站内大佬的帖子跑成功的,全程在服务器终端进行操作,蓝字是我自己写的,黑字是readme上面的
nnU-Netv2在服务器上使用全流程(小白边踩坑边学习的记录)-CSDN博客
nnU-Net v2的环境配置到训练自己的数据集(详细步骤)_nnunetv2-CSDN博客
一、硬件要求
GPU:需要至少拥有10 GB的GPU(我电脑的8g不行)
CPU:6核(12线程)
例:
1、用于训练的示例工作站配置:
CPU:Ryzen 5800X - 5900X或7900X将更好!
GPU:RTX 3090或RTX 4090(我用的是AutoDL上租的4090)
RAM:64GB
存储:SSD(M.2 PCIe Gen 3或更好!)
2、用于训练的示例服务器配置:
CPU:2x AMD EPYC7763,总共128C/256T。对于像A100这样的快速GPU,强烈推荐16C/GPU!
GPU:8xA100 PCIe(价格/性能优于SXM变体+它们的功耗更低)
RAM:1 TB
存储:本地SSD存储(PCIe Gen 3或更好)或超快速网络存储 (nnU-net默认使用每个训练一个GPU。服务器配置可以同时运行多达8个模型训练)
二、环境配置
建议在虚拟环境中安装nnU-Net!我自己创建了一个叫nnunet_env的虚拟环境,以后的几乎每一步操作都要先激活环境
conda create -n nnunet_env python=3.91、安装按PyTorch(在虚拟环境下)
安装支持硬件的最新版本(cuda、mps、cpu)。可以输入nvidia-smi查看配置,去pytorch官网下载。PyTorch
2、安装nnU-Net
(1)用作标准化基线、开箱即用的分割算法或使用预训练模型进行推断:
pip install nnunetv2
(2) 用作综合框架(我用这个,因为可以改代码,建议用这个,下面几行是依次输入,不是一起)
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
3、安装hiddenlayer
hiddenlayer使nnU-net能够生成其生成的网络拓扑的图表(请参阅模型训练)。要安装hiddenlayer,请运行以下命令:
pip install --upgrade git+https://github.com/FabianIsensee/hiddenlayer.git
三、数据转换
将数据导入nnU-Net的唯一方法是将其存储在特定格式中。数据集包括三个组件:原始图像、对应的分割地图和一个指定一些元数据的dataset.json文件。
1、命名格式
nnU-Net通过其文件末尾的四位数字来识别输入通道:一个四位数的整数。因此,图像文件必须遵循以下命名约定:{CASE_IDENTIFIER}_{XXXX}.{FILE_ENDING}。FILE_ENDING是图像格式使用的文件扩展名(.png,.nii.gz,...)。dataset.json文件将通道名称与'channel_names'键中的通道标识符连接起来。不要使用.jpg之类的文件格式!
2、数据文件结构
(1、先在nnUNet下新建一个文件夹DATASET,
2、再在DATASET下新建三个文件夹,nnUNet_raw、nnUNet_preprocessed 和 nnUNet_trained_models,
3、接着在nnUNet_raw里面新建数据集文件,注意命名格式
4、在数据集文件中新建imagesTr和labelsTr,并上传文件,还要json文件)
数据集必须位于nnUNet_raw文件夹中(您在安装nnU-Net时定义的,或者每次打算运行nnU-Net命令时导出/设置的!)。每个分割数据集都存储为单独的“Dataset”。数据集与数据集ID(三位整数)和数据集名称(您可以自由选择)相关联
nnUNet_raw/
├── Dataset001_BrainTumour
├── Dataset002_Heart
├── Dataset003_Liver
├── Dataset004_Hippocampus
├── Dataset005_Prostate
├── ...
在每个数据集文件夹中,期望以下结构:
Dataset001_BrainTumour/
├── dataset.json
├── imagesTr
├── imagesTs # optional
└── labelsTr
imagesTr:包含属于训练案例的图像。nnU-Net将使用此数据执行管道配置、交叉验证训练以及查找后处理和最佳集成。imagesTs(可选):包含属于测试案例的图像。nnU-Net不会使用它们!这只是一个方便您存储这些图像的地方。医学分割十项全能赛文件夹结构的剩余部分。labelsTr:包含训练案例的地面真实分割地图的图像。dataset.json:包含数据集的元数据。
3、dataset.json文件
(我直接就用示例改了下, "numTraining"是样本数量)
dataset.json文件包含nnU-Net训练所需的元数据,以下是Dataset005_Prostate的示例,展示了dataset.json应该是什么样子:
{
"channel_names": { # formerly modalities
"0": "T2",
"1": "ADC"
},
"labels": { # THIS IS DIFFERENT NOW!
"background": 0,
"PZ": 1,
"TZ": 2
},
"numTraining": 32,
"file_ending": ".nii.gz",
"overwrite_image_reader_writer": "SimpleITKIO" # optional! If not provided nnU-Net will automatically determine the ReaderWriter
}
有一个工具可以自动生成dataset.json。您可以在这里找到它。请参考我们的示例dataset_conversion中如何使用它。并阅读其文档!
四、实现
在实现之前有个很重要的环境变量改变,去shell里加上DATSET下三个子文件的路径,
1、终端输入:vi ~/.bashrc
2、按E进入编辑
3、拉到最下面,按i进入编辑模式,粘贴自己的路径,最后按esc退出到终端
4、终端输入:source ~/.bashrc 才能保存。
export nnUNet_preprocessed="autodl-tmp/nnUNet/DATASET/nnUNet_preprocessed" export nnUNet_results="autodl-tmp/nnUNet/DATASET/nnUNet_trained_models" export nnUNet_raw="autodl-tmp/nnUNet/DATASET/nnUNet_raw"
1、运行指纹提取、实验规划和预处理
给定一个新的数据集,nnU-Net将提取数据集指纹(一组数据集特定属性,如图像尺寸、体素间距、强度信息等)。
运行指纹提取、实验规划和预处理的最简单方法是使用:
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity
nnUNetv2_plan_and_preprocess 将在您的 nnUNet_preprocessed 文件夹中创建一个名为数据集的新子文件夹。一旦命令完成,您将看到一个 dataset_fingerprint.json 文件和一个 nnUNetPlans.json 文件(如果您感兴趣的话)。此外,还将创建包含您的UNet配置预处理数据的子文件夹。
我的就是029,因为029是我的数据集id
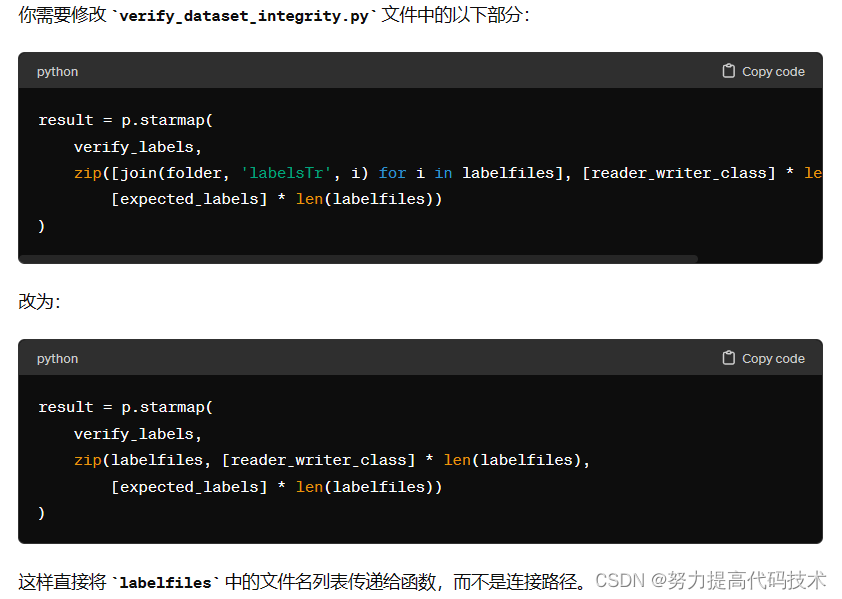
nnUNetv2_plan_and_preprocess -d 029 --verify_dataset_integrity但我这个出现了问题,显示labelsTr路径重复。出现这个错误的就去verify_dataset_integrity.py把代码改了(nnUNet/nnunetv2/experiment_planning/verify_dataset_integrity.py,204行附近)
改之后代码:
result = p.starmap( verify_labels, zip(labelfiles, [reader_writer_class] * len(labelfiles),[expected_labels] * len(labelfiles)) )
2、模型训练
我是一行一行训练的,依次输入,训练完一个了再输入下一个,我是2d数据
如果想停止就按ctrl+c,想继续训练就原始代码后面加上--c,注意跟原始代码直接有空格
想改变训练次数就去nnUNet/nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py里修改,145行
nnUNetv2_train 029 2d 0 nnUNetv2_train 029 2d 1 nnUNetv2_train 029 2d 2 nnUNetv2_train 029 2d 3 nnUNetv2_train 029 2d 4
nnU-Net 在训练案例的 5 折交叉验证中训练所有配置。这一步骤是必要的,因此 nnU-Net 可以估计每个配置的性能,并告诉您哪个应该用于您的分割问题,并且 2) 获得一个良好的模型集成(对这 5 个模型的输出进行平均预测)以提高性能。
5折交叉验证:是一种常用的模型评估技术,通常用于评估机器学习模型的性能。在5折交叉验证中,数据集被随机分成5个相等的子集,其中的4个子集被用作训练数据,而剩余的一个子集被用作验证数据。模型会被训练5次,每次使用其中一个子集作为验证集,而其他4个子集作为训练集。然后,对这5次训练的结果进行平均,以得到最终的性能评估指标。
模型训练是使用 nnUNetv2_train 命令完成的。该命令的一般结构如下:
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD [additional options, see -h]
UNET_CONFIGURATION 是一个字符串,用于标识请求的 U-Net 配置(默认值:2d、3d_fullres、3d_lowres、3d_cascade_lowres)。DATASET_NAME_OR_ID 指定应该在其上进行训练的数据集,FOLD 指定进行训练的 5 折交叉验证的哪一折。
2D U-Net 对于每个FOLD在[0, 1, 2, 3, 4]中,运行以下命令:
nnUNetv2_train DATASET_NAME_OR_ID 2d FOLD [--npz]
3D全分辨率U-Net 对于每个FOLD在[0, 1, 2, 3, 4]中,运行以下命令:
nnUNetv2_train DATASET_NAME_OR_ID 3d_fullres FOLD [--npz]
3D U-Net级联 对于每个FOLD在[0, 1, 2, 3, 4]中,运行以下命令:
nnUNetv2_train DATASET_NAME_OR_ID 3d_cascade_fullres FOLD [--npz]
每个模型训练的输出文件夹中(每个fold_x文件夹中),将创建以下文件:
- debug.json:包含用于训练该模型的蓝图和推断参数的摘要,以及一堆其他信息。难以阅读,但对于调试非常有用 ;-)
- checkpoint_best.pth:在训练过程中识别出的最佳模型的检查点文件。目前未使用,除非您明确告诉nnU-Net要使用它。
- checkpoint_final.pth:最终模型的检查点文件(在训练结束后)。这用于验证和推理。
- network_architecture.pdf(仅在安装了hiddenlayer时!):一个包含网络架构图的pdf文档。
- progress.png:显示了训练过程中的损失、伪Dice、学习率和epoch时间。在顶部是训练(蓝色)和验证(红色)损失在训练过程中的绘图。还显示了Dice的近似值(绿色),以及它的移动平均值(虚线绿色线)。这个近似值是前景类的平均Dice分数。需要注意的是,这是根据训练过程中从验证数据中随机抽取的补丁计算的,而不是针对每个验证案例计算并平均的Dice,而是假装只有一个验证案例从中抽取补丁。这样做的原因是'全局Dice'在训练期间易于计算,并且仍然非常有用,可以评估模型是否在训练过程中。真正的验证需要太长时间才能在每个epoch中完成。它是在训练结束时运行的。
- validation_raw:在训练结束后,此文件夹中包含预测的验证案例。此处的summary.json文件包含验证指标(在文件开头提供了所有案例的平均值)。如果设置了--npz,则这里还会有压缩的softmax输出(保存为.npz文件)。
