
阅读量:0
前言
在人工智能技术飞速发展的今天,如何高效地在CPU上运行大规模的预训练语言模型(LLM)成为了加速生成式AI应用广泛落地的核心问题。阿里巴巴达摩院模型开源社区ModelScope近期推出了一款名为DashInfer的推理引擎,旨在解决这一挑战。
DashInfer用于推理预训练大语言模型(LLM)的推理引擎。
DashInfer采用C++ Runtime编写,提供C++和Python语言接口。DashInfer具有生产级别的高性能表现,适用于多种CPU架构,包括x86和ARMv9。DashInfer支持连续批处理(Continuous Batching)和多NUMA推理(NUMA-Aware),能够充分利用服务器级CPU的算力,为推理14B及以下的LLM模型提供更多的硬件选择。
不想看理论的小伙伴可以直接跳转到实战了:基于魔搭开源推理引擎 DashInfer实现CPU服务器大模型推理--实战篇-CSDN博客
DashInfer介绍
轻量级架构:仅需要最小程度的第三方依赖,并采用静态链接的方式引用依赖库。提供C++和Python接口,让DashInfer可以轻松集成到您的系统和其他编程语言中。
提供高精度实现:DashInfer经过严格的精度测试,能够提供与PyTorch、GPU引擎(vLLM)一致的推理精度。
优化的计算Kernel:结合OneDNN和自研汇编kernel,DashInfer能够在ARM和x86上发挥硬件的最大性能。ARM cpu+单batch条件下,推理Llama2-7B-Chat的16-bit权重和8-bit权重模型,DashInfer的生成性能分别是llama.cpp的1.5倍和1.9倍,详细性能测试结果参考performance.md
(https://github.com/modelscope/dash-infer/blob/main/documents/EN/performance.md)。
行业标准LLM推理技术:采用行业标准的LLM推理技术,例如:
连续批处理(Continuous Batching),能够进行即时插入新请求,支持流式输出;
基于请求的异步接口允许对每个请求的生成参数、请求状态等进行单独控制。
支持主流LLM开源模型:支持主流的开源LLM模型,包括Qwen、LLaMA、ChatGLM等,支持Huggingface格式的模型读取。
PTQ量化:使用DashInfer的InstantQuant(IQ),无需训练微调即可实现weight-only量化加速,提高部署效率。经过精度测试,IQ对模型精度不会产生影响。目前版本支持ARM CPU上的weight-only 8-bit量化。
优化的计算Kernel:结合OneDNN和自研汇编kernel,DashInfer能够在ARM和x86上发挥硬件的最大性能。
NUMA-Aware:支持多NUMA的tensor并行推理,充分发挥服务器级CPU的算力。通过numactl和多进程架构,精准控制计算线程的NUMA亲和性,充分利用多节点CPU的性能,并且避免跨NUMA访存带来性能下降问题。关于多NUMA的性能指导可以参考:Optimizing Applications for NUMA - Intel, What is NUMA?。
上下文长度(Context Length):目前版本支持11k的Context Length,未来还会继续支持更长Context Length。
提供多语言API接口:提供C++和Python接口,能够直接使用C++接口对接到Java、Rust等其他编程语言。
操作系统支持:支持Centos7、Ubuntu22.04等主流Linux服务器操作系统,并提供对应的Docker镜像。
硬件支持和数据类型
硬件支持
x86 CPU:
要求硬件至少需要支持AVX2指令集。对于第五代至强(Xeon)处理器(Emerald Rapids)、第四代至强(Xeon)处理器(Sapphire Rapids)等(对应于阿里云第8代ECS实例,如g8i),采用AMX矩阵指令加速计算。
ARMv9 CPU:
要求硬件支持SVE指令集。支持如倚天(Yitian)710等ARMv9架构处理器(对应于阿里云第8代ECS实例,如g8y),采用SVE向量指令加速计算。
数据类型
x86 CPU:支持FP32、BF16。
ARM Yitian710 CPU:FP32、BF16、InstantQuant。
InstantQuant
InstantQuant是一种weight-only量化技术。
在Yitian710 CPU(ARMv9)上,DashInfer支持weight-only量化。
要进行weight-only量化,需要修改模型配置文件的do_dynamic_quantize_convert和quantization_config字段,参数的详细说明参考Github。
weight-only量化,会在GroupSize的范围内求取weight的最大、最小值,并将weight数值映射到uint8的值域范围,计算公式如下:
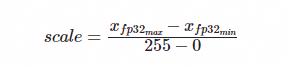
推理过程中,量化的weight会被恢复成bfloat16进行矩阵乘法计算。
软件框架
推理流程
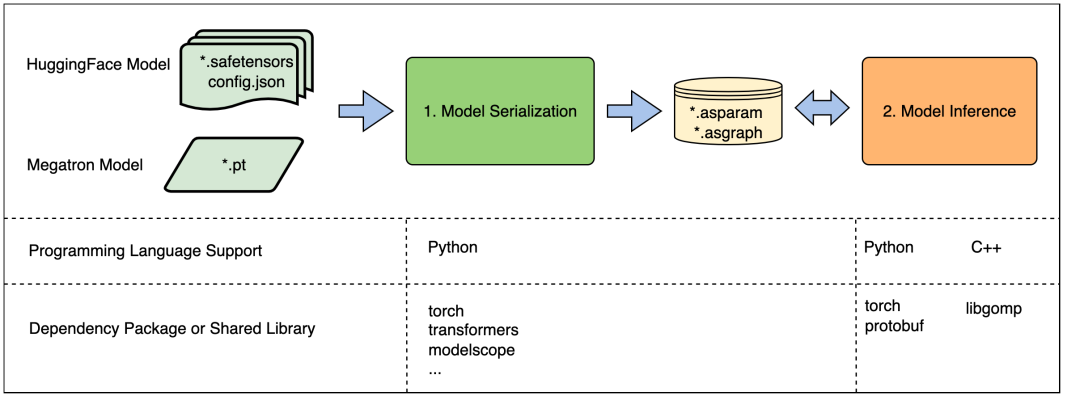
模型加载与序列化:此过程负责读取模型权重、配置模型转换参数及量化参数,并根据这些信息对模型进行序列化,并生成DashInfer格式(.asparam、.asgraph)的模型。此功能仅提供Python接口,并依赖于PyTorch和transformers库来访问权重。不同模型对PyTorch和transformers的版本要求可能有所不同,DashInfer本身并没有特殊的版本要求。
模型推理:此步骤负责执行模型推理,使用DashInfer推理序列化后的模型,不依赖PyTorch等组件。DashInfer采用DLPack格式的tensor来实现与外部框架(如PyTorch)的交互。DLPack格式的tensor,可以通过手动创建或由深度学习框架的tensor转换函数产生。对于C++接口,由于已经将几乎所有依赖静态编译,仅对openmp运行时库以及C++系统库的有依赖。我们进行了链接符号处理,以确保只有DashInfer的API接口符号可见,避免与客户系统中已有的公共库(如protobuf等)发生版本冲突。
说明: .asparam、.asgraph是由DashInfer内核(allspark)定义的一种特殊的模型格式。 使用Python接口时,可以将步骤1和2的代码放在一起。由于缺少C++层面加载Huggingface模型的功能,C++接口只能进行DashInfer格式的模型推理,因此在使用C++接口前,必须先用Python接口先对模型进行序列化。代码开源地址:
https://github.com/modelscope/dash-infer
推理体验地址:
https://www.modelscope.cn/studios/modelscope/DashInfer-Demo
