
阅读量:9

引言
说到大语言模型相信大家都不会陌生,大型语言模型(LLMs)是人工智能文本处理的主要类型,也现在最流行的人工智能应用形态。ChatGPT就是是迄今为止最著名的使用LLM的工具,它由OpenAI的GPT模型的特别调整版本提供动力,而今天我们就来带大家体验一下部署大模型的实战。
文章目录
一、项目选择与系统介绍
1.1 项目介绍
本来博主是准备来部署一下咱们的,清华大语言模型镜像这个目前也是非常的火啊,吸引了很多人的注意其优秀的性能和GPT3 不相上下,但是由于考虑到,大部分人电脑其实跑大模型是有一点点吃力的,为了让更多人来先迈出部署模型的第一步,于是就决定去 gitee 上找一个小型一点的大模型来实战一下。
1.2 Tiny-Llama语言模型
- 果不其然刚搜索就发现 一个基于香橙派AI Pro 部署的语言大模型项目,这不正好吗?直接开始
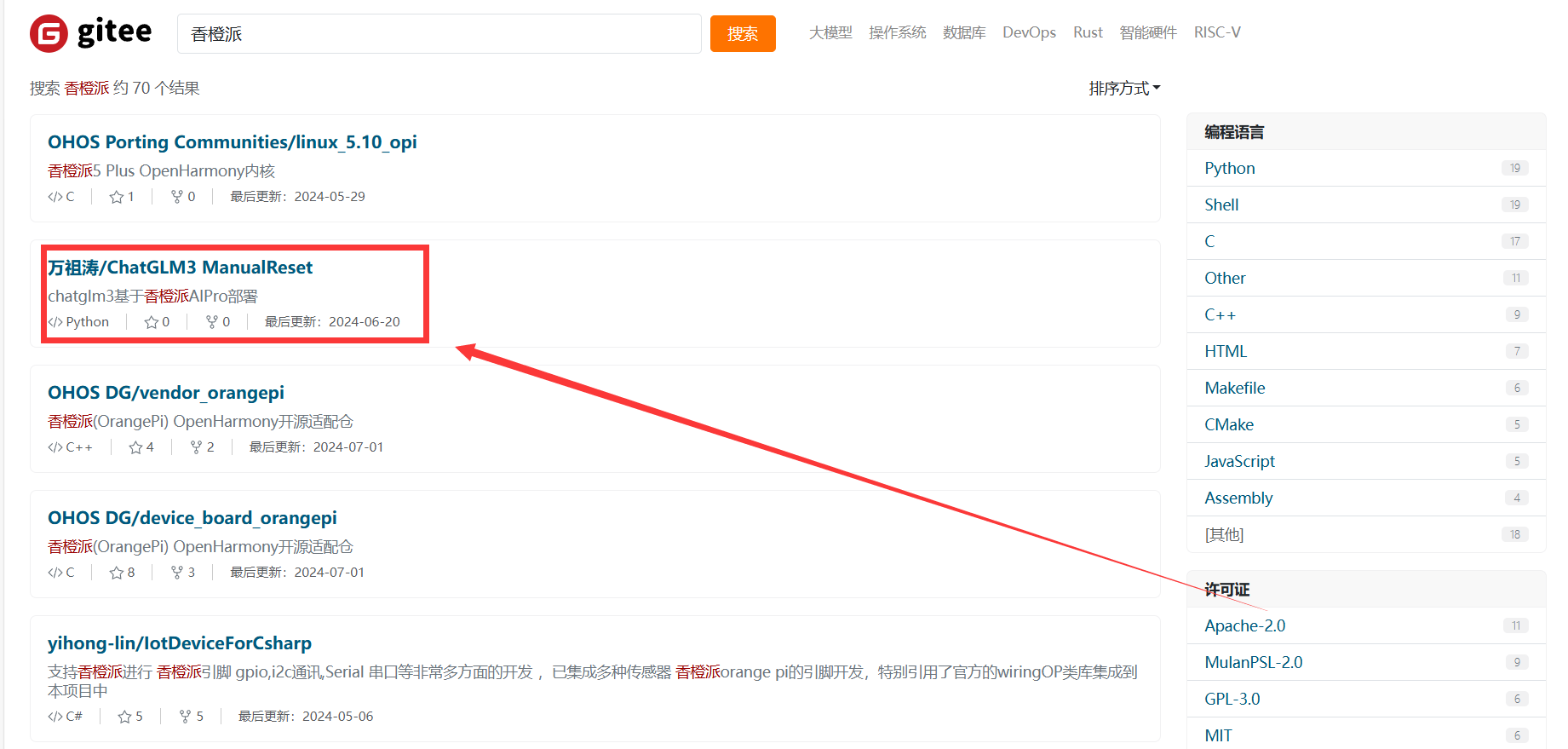
- 点进去一看发现这是南京大学开源的一套基于香橙派 AIpro部署的Tiny-Llama语言模型
- (开源地址)
1.3 进入系统
这里我们选择的是openEuler,是香橙派的这块板子内置的系统。但其实他的内核是ubuntu这里可以给大家看一下,所以我们用 ubuntu 服务器来部署应该是没有问题的。
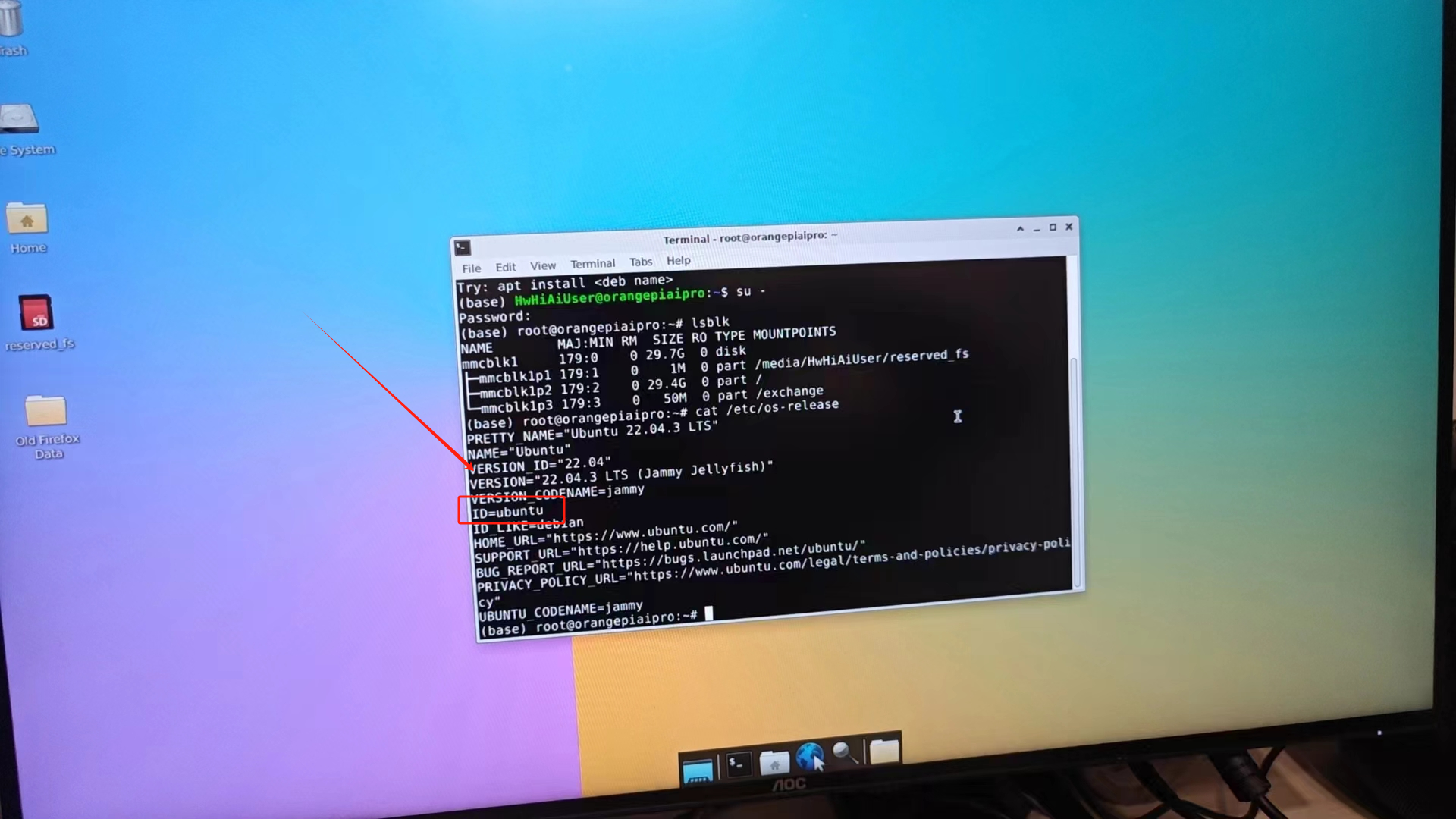
openEuler 是一由中国开源软件基金会主导,以Linux稳定系统内核为基础,华为深度参与,面向服务器、桌面和嵌入式等的一个开源操作系统。
1.4 进行远程连接
这里直接插电启动,默认用户名
HwHiAiUser、密码Mind@123当然root密码也是一样的这里我们进来之后可以直接选择链接WiFi 非常便捷
当然这里大家在这里也可以选择云服务器远程实战

- 然后我们打开命令窗查看IP , 由于系统默认支持ssh 远程连接,所以博主这里就直接采用 Sxhell 进行连接
- 输入ip 选择
HwHiAiUser登录 密码Mind@123
二、部署LLMS大模型
2.1 拉取代码到环境
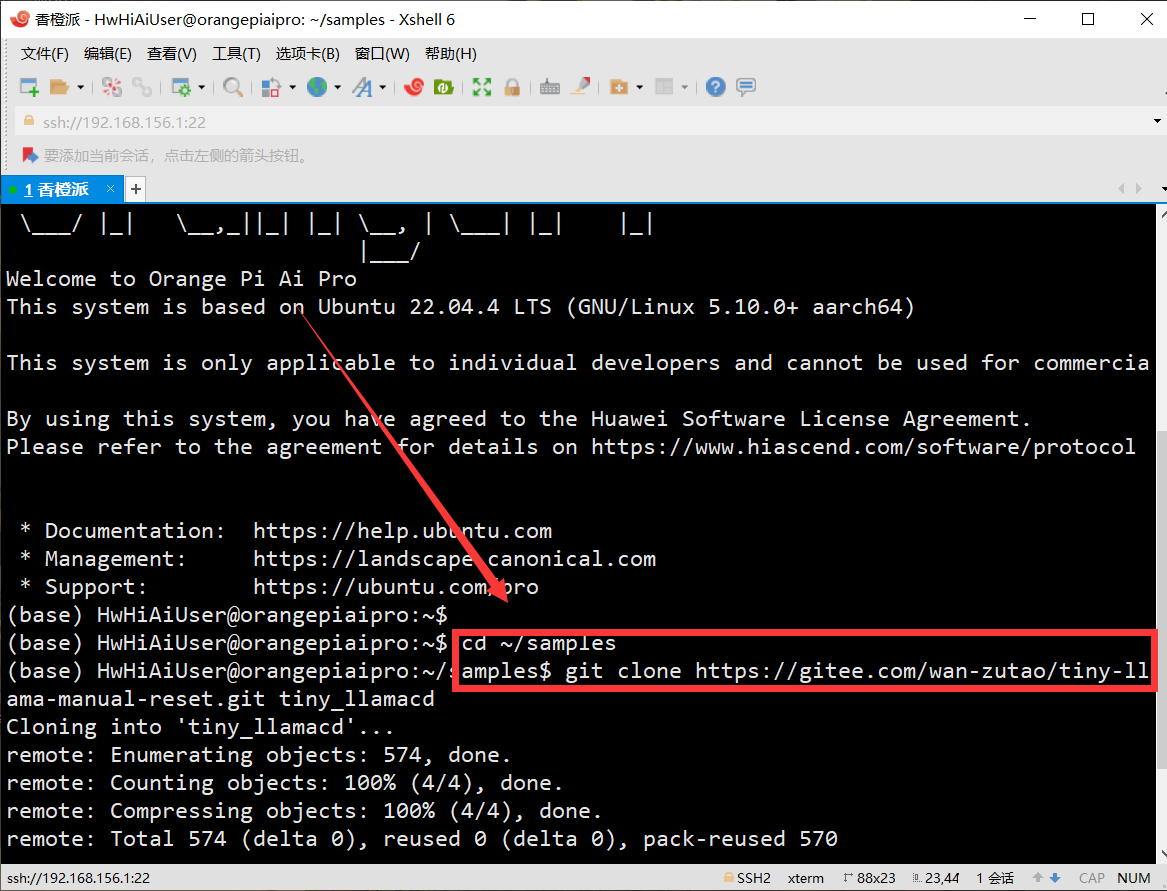
- 先cd进入
cd ~/samples目录 - 之后直接利用git 拉取我们的项目,git 由于系统镜像自带的有就不用我们手动安装了
2.2 自定义算子部署
配置protoc 环境
- 使用wget工具从指定的华为云链接下载 protobuf-all-3.13.0.tar.gz文件
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/protobuf-all-3.13.0.tar.gz --no-check-certificate 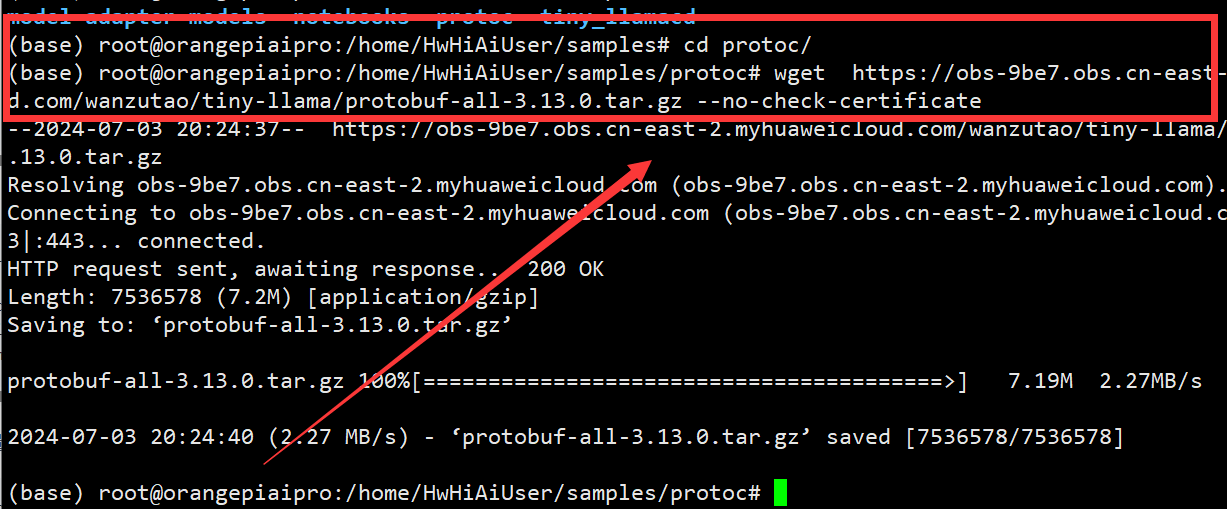
- 解压刚刚下载的文件
tar -zxvf protobuf-all-3.13.0.tar.gz 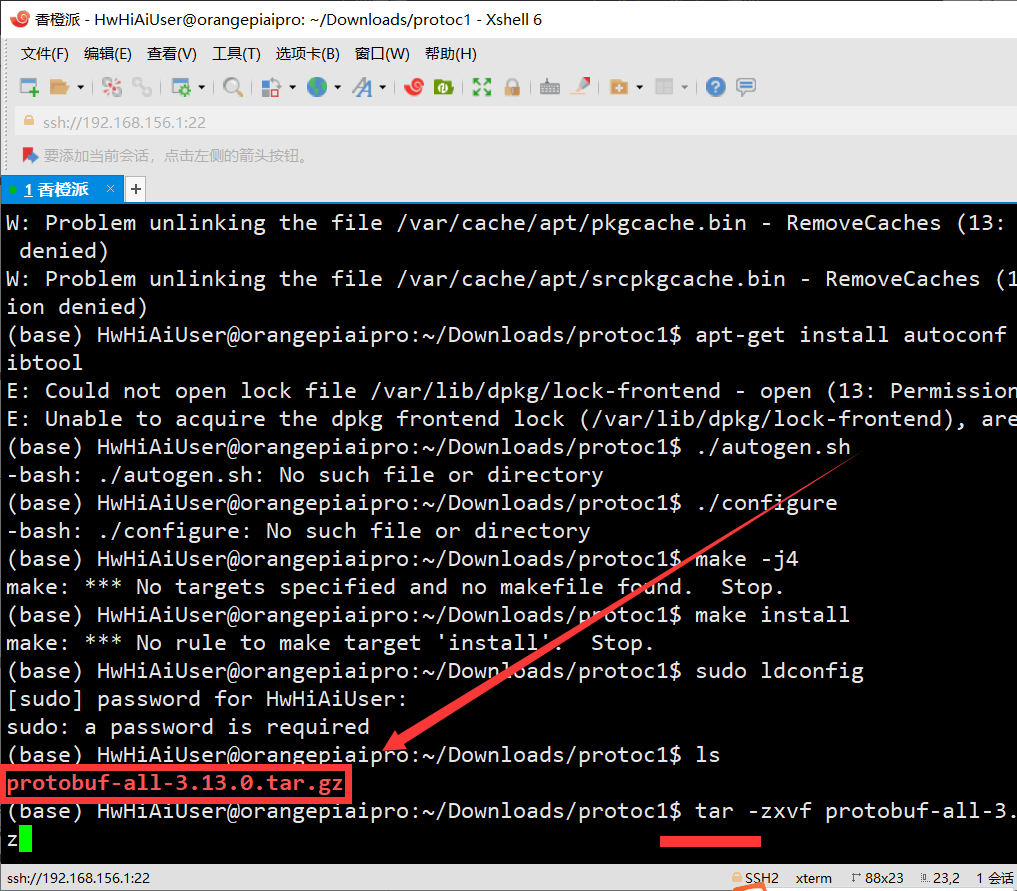
这里解压速度非常快,基本一秒就OK了
- 进入 protobuf-3.13.0 文件夹中
cd protobuf-3.13.0 更新apt包管理器的软件包列表
apt-get update 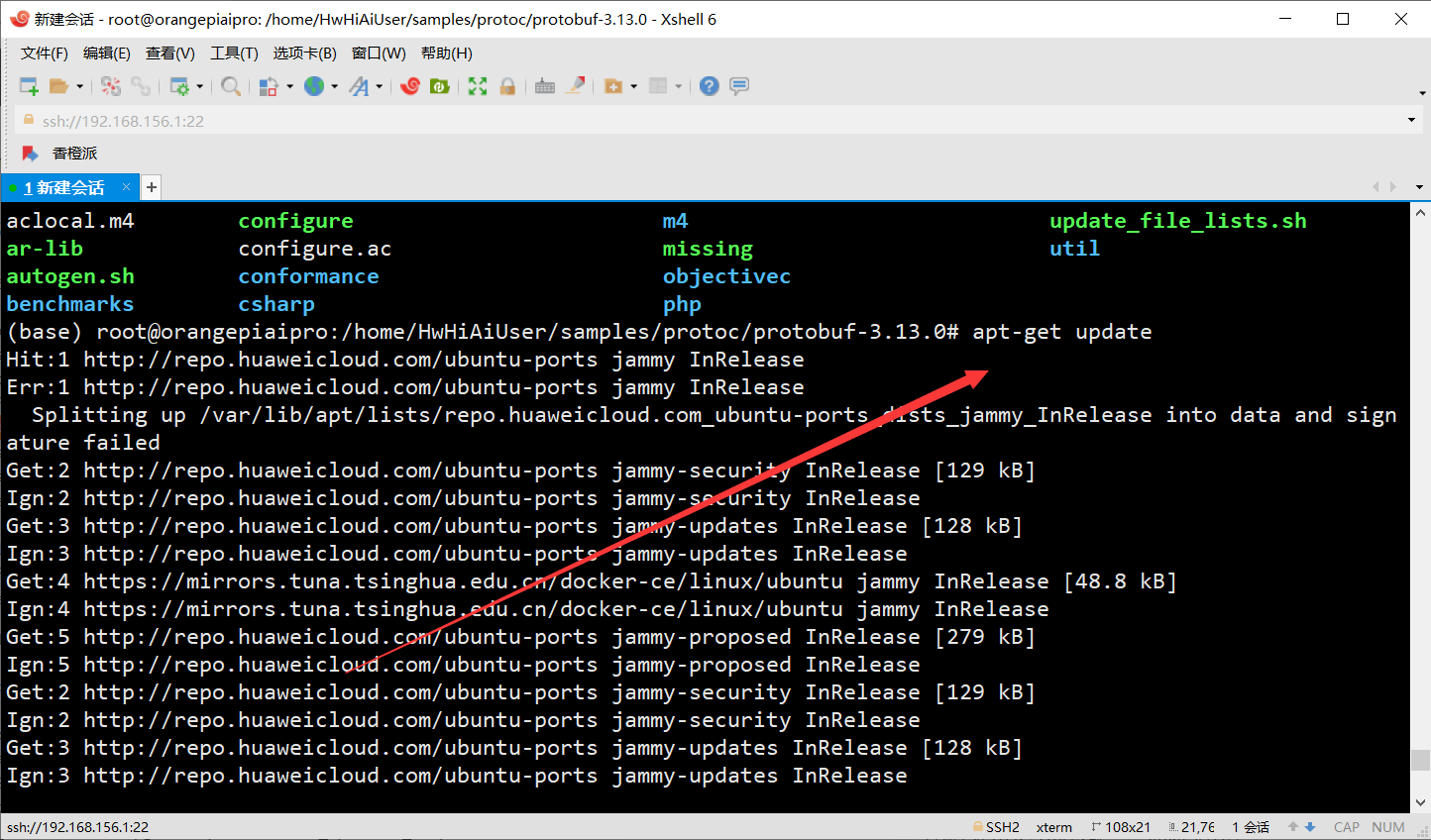
- 使用apt-get安装必要的构建工具,包括autoconf、automake和libtool,这些工具用于配置和构建开源项目
apt-get install autoconf automake libtool 
- 生成配置脚本
configure, 运行./configure生成一个Makefile
./autogen.sh ./configure - 编译源代码,由于
香橙派 AIpro是4核64位处理器+ AI处理器支持8个线程,我们我们可以大胆的使用4个并行进程进行编译,以加快编译速度。 - 编译这里的时候大家就可以放松放松了大概只需要10几分钟就好了
make -j4 
- 将编译后的二进制文件和库文件安装到系统指定的位置
make install 
- 更新系统共享库缓存的工具,检查protoc 版本
sudo ldconfig protoc --version 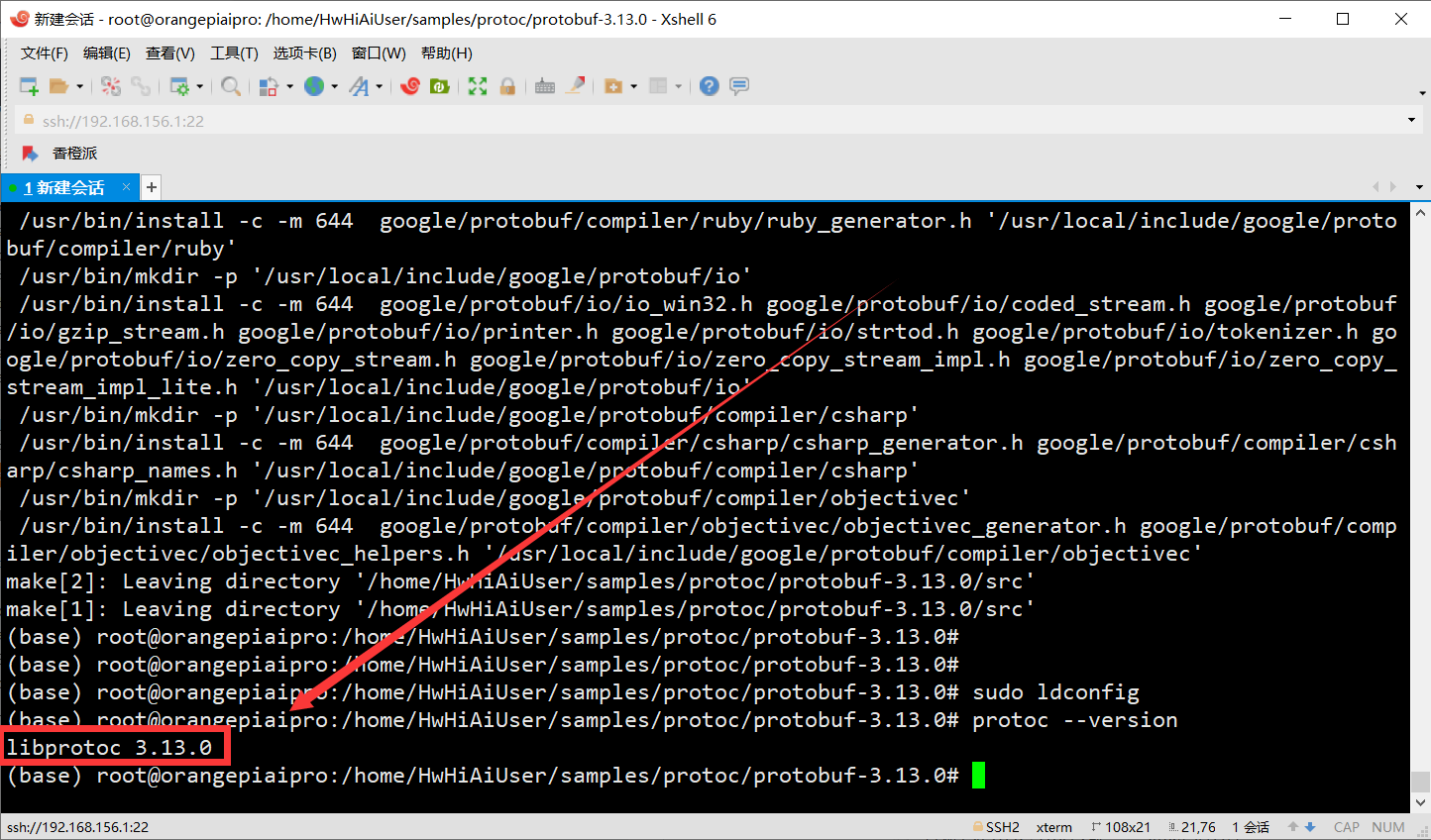
算子编译部署
- 将当前工作目录切换到
tiny_llama

- 设置了一个环境变量 ASCEND_PATH,并将其值设为
/usr/local/Ascend/ascend-toolkit/latest export ASCEND_PATH=/usr/local/Ascend/ascend-toolkit/latest
- 将
custom_op/matmul_integer_plugin.cc文件复制到指定路径
cp custom_op/matmul_integer_plugin.cc $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx/framework/onnx_plugin/ - cd 进入 目标文件夹进行配置
cd $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx 
修改环境变量
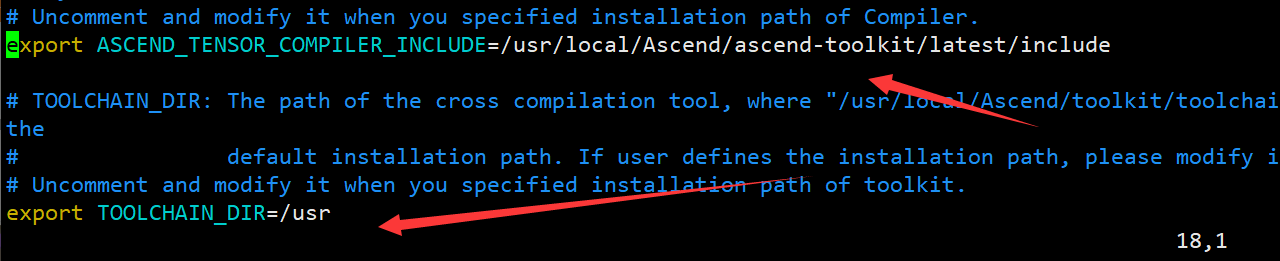
- 打开build.sh,找到下面四个环境变量,解开注释并修改如下:
#命令为 vim build.sh 
# 修改内容为 export ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/include export TOOLCHAIN_DIR=/usr export AICPU_KERNEL_TARGET=cust_aicpu_kernels export AICPU_SOC_VERSION=Ascend310B4 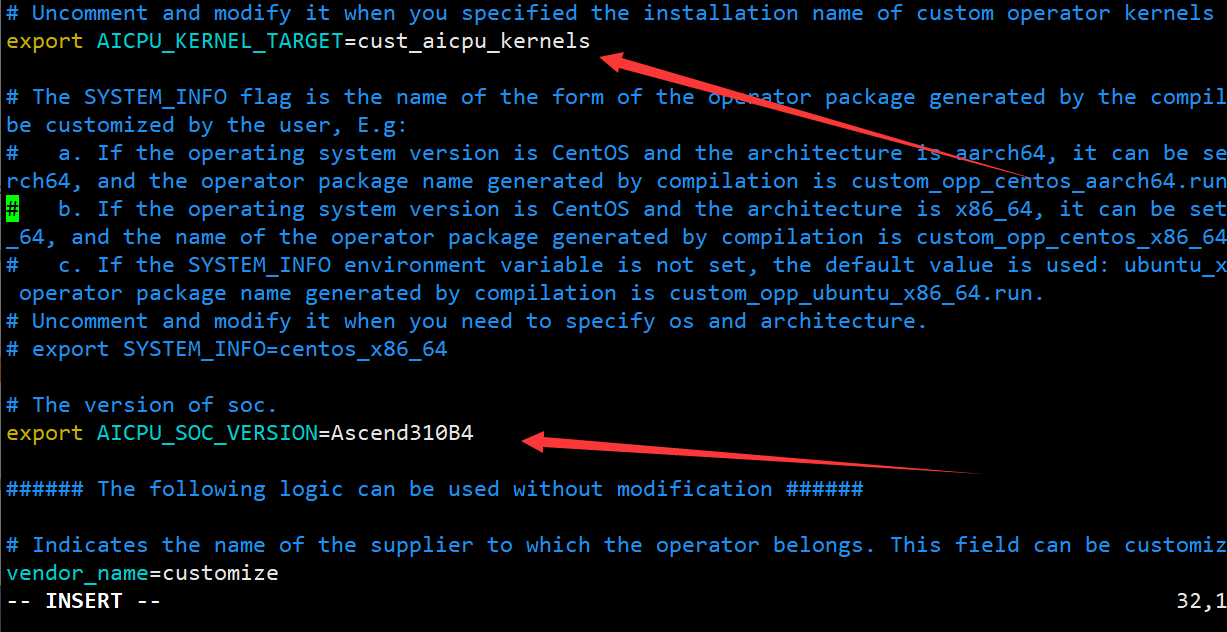
编译运行& 依赖安装
- 编译构建项目,进入到构建输出目录以后续处理生成的文
./build.sh cd build_out/ 
- 生成文件到
customize到默认目录$ASCEND_PATH/opp/vendors/
./custom_opp_ubuntu_aarch64.run - 删除冗余文件
cd $ASCEND_PATH/opp/vendors/customize rm -rf op_impl/ op_proto/ 
- 安装依赖:从指定的华为云 PyPI 镜像源安装所需的 Python 包
cd tiny_llama/inference pip install -r requirements.txt -i https://mirrors.huaweicloud.com/repository/pypi/simple - 先cd 回到根目录,在进入家目录,找到咱们的
tiny_llama/inference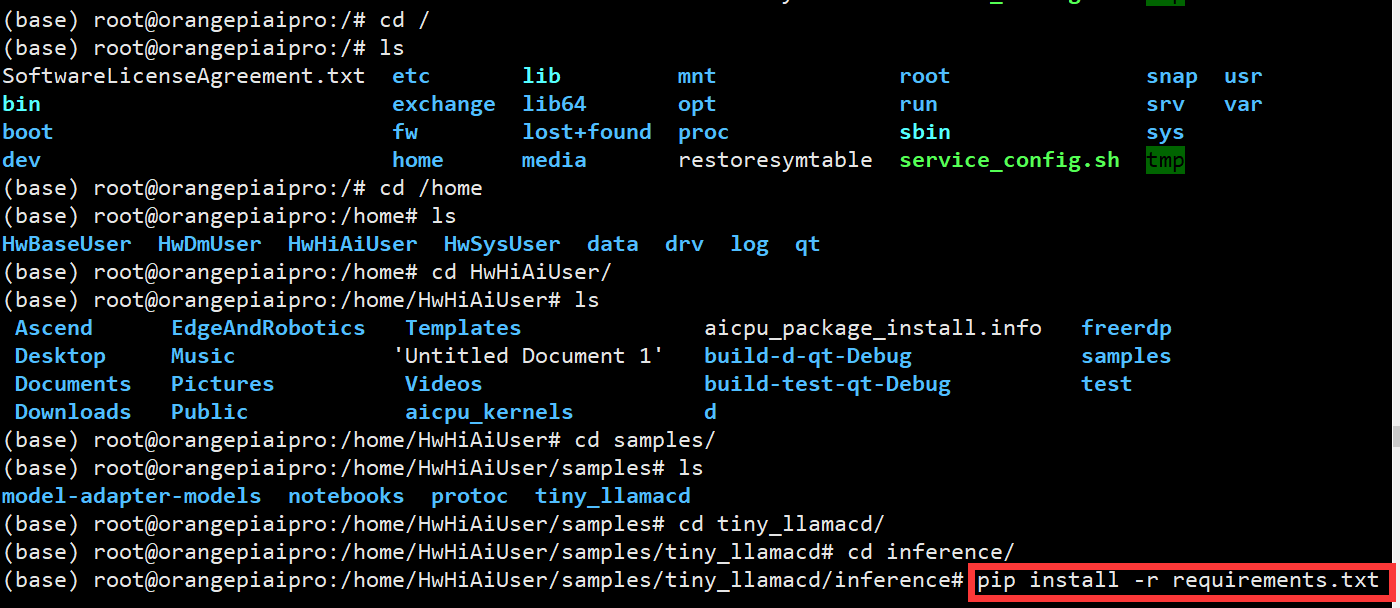
2.3 推理启动
- 下载tokenizer文件
cd tokenizer wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/tokenizer.zip unzip tokenizer.zip 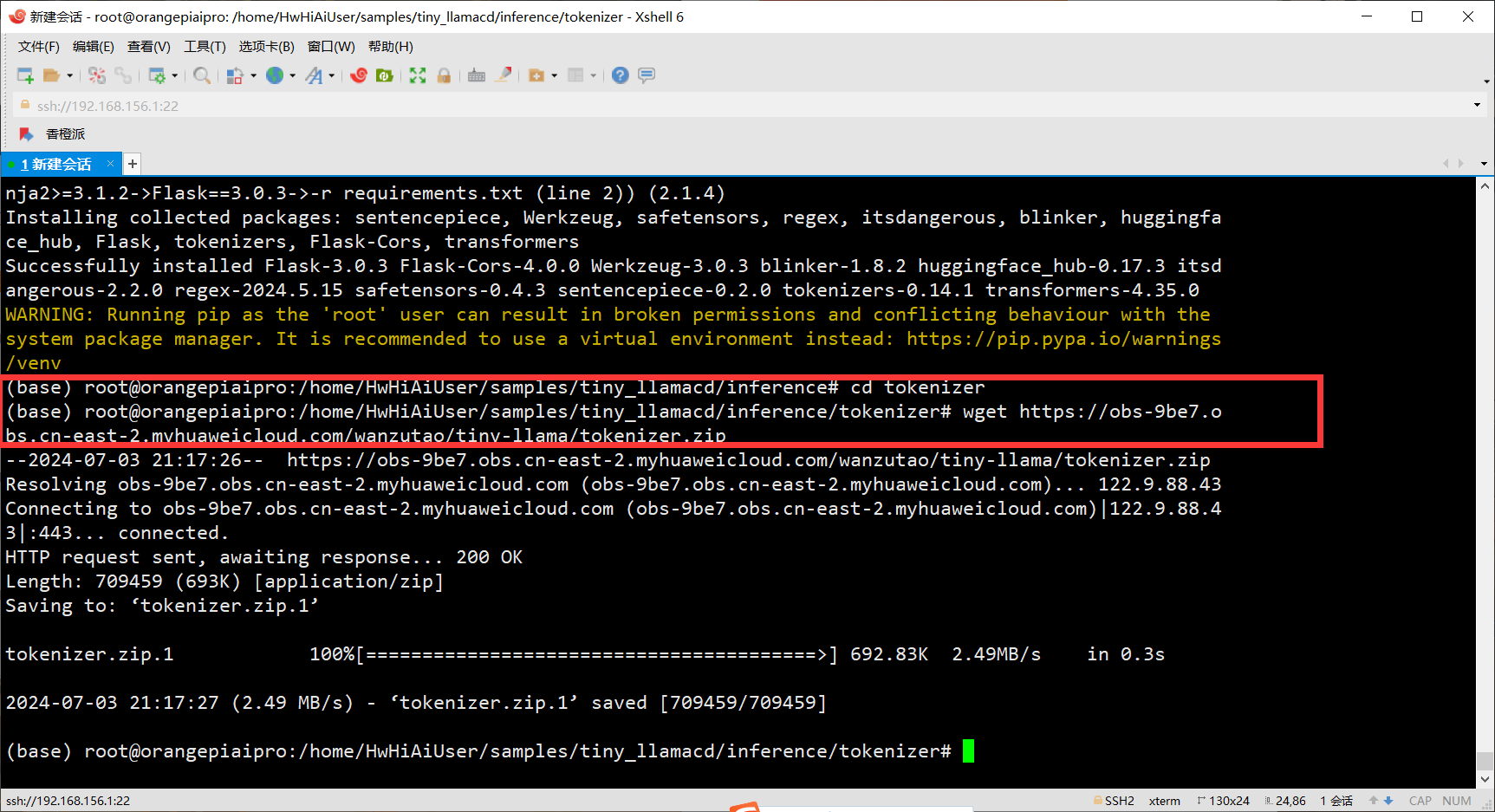
- 获取onnx模型文件
cd ../model wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/tiny-llama.onnx 我们在复制代码的时候一定要仔细嗷博主这里少打了一个w 导致并没有获取到模型,后期找了半天才发现错误所以提醒大家一定要注意好每一步

atc模型转换
atc --framework=5 --model="./tiny-llama.onnx" --output="tiny-llama" --input_format=ND --input_shape="input_ids:1,1;attention_mask:1,1025;position_ids:1,1;past_key_values:22,2,1,4,1024,64" --soc_version=Ascend310B4 --precision_mode=must_keep_origin_dtype 
三、 项目体验
好了到这里我们就算是大功告成了,只需要启动一下mian文件就OK了
- 在
cd tiny_llama/inference目录下运行命令
python3 main.py 
- 打开网址进行访问
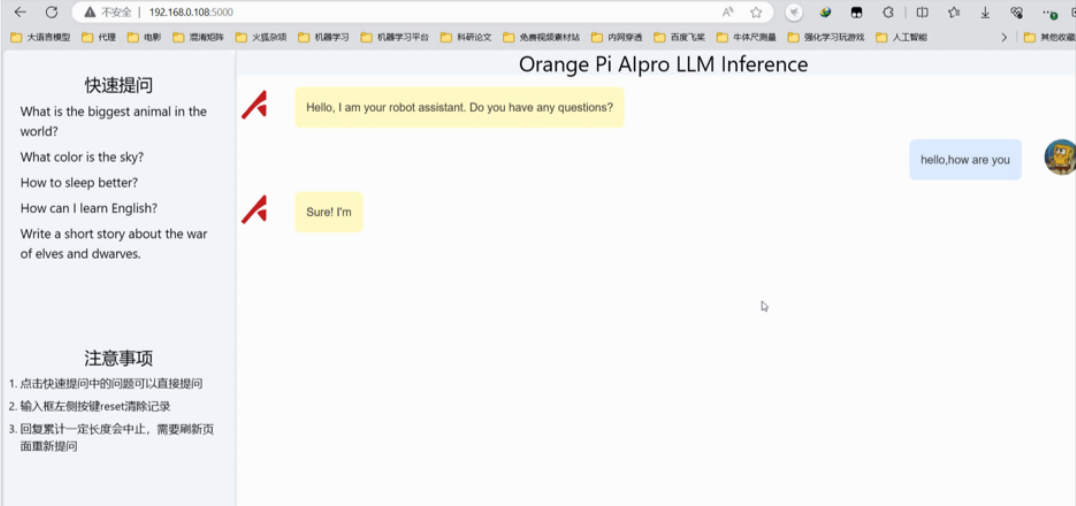
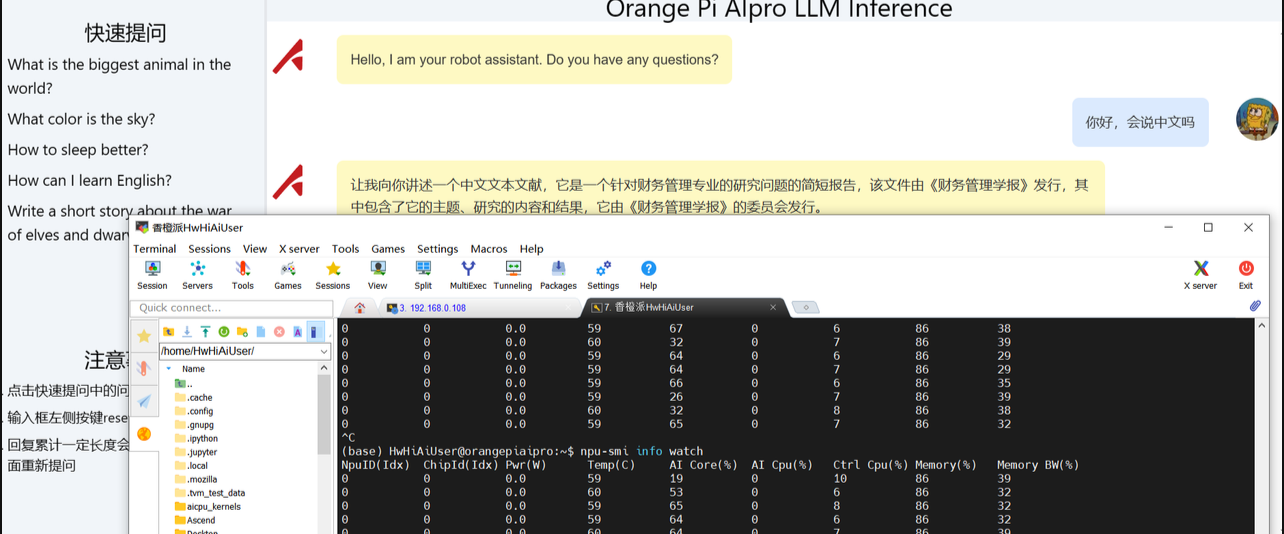
Tiny-Llama这个模型由于尺寸非常小,参数也只有1.1B。所以在我们部署Tiny-Llama这个大语言模型推理过程中,Ai Core的占用率只到60%左右,基本是一秒俩个词左右,速度上是肯定没问题的。后期可以去试试升级一下内存去跑一下当下主流的 千问7B模型 或者 清华第二代大模型拥有 60 亿参数 ChatGLM2 感觉用
OrangePi AIpro这块板子也是没问题。
